本文记录文生图、文生视频的相关论文。
Breathing Life Into Sketches Using Text-to-Video Priors
( Citation: Gal, Vinker & al., 2023 Gal, R., Vinker, Y., Alaluf, Y., Bermano, A., Cohen-Or, D., Shamir, A. & Chechik, G. (2023). Breathing Life Into Sketches Using Text-to-Video Priors. https://doi.org/10.48550/arXiv.2311.13608 ) 是英伟达在CVPR2024的一篇论文,研究如何将草图和描述文本转化为视频(demo地址)。
草图是人们表达想法的直观有效工具,利用草图生成视频能进一步丰富草图的直观表达功能。现有方法依赖人工标定的关键点或人工标定的草图含义,不够灵活,本文利用预训练的文生视频扩散模型,免去人工操作,自动生成草图视频。尽管已有由静态图生成视频的工作,但它们不能很好地应用于草图这种特殊的静态图。
本文提出的模型包含两个输入:草图和描述文本。只需要使用输入对模型进行训练,无需额外数据对扩散模型进行微调。换句话说,本文直接利用扩散模型的信息对小模型进行优化。
草图的矢量表示
考虑矢量图。矢量图不受分辨率限制,即放大多少倍也不会影响图片的质量;同时矢量图具有更加紧致、容易修改等特性。一种流行的矢量图格式是SVG(Scalable Vector Graphics)。
矢量图由若干条“笔画”构成,每个笔画是一条三次贝塞尔曲线,即每个笔画由4个2D空间的点控制。因此,一张静态草图可以由控制点的序列表示,即
$$P=\{p_1,\cdots,p_N\}\in\mathbb{R}^{N\times 2}$$
本文假设视频的所有帧中的控制点个数保持不变,即$N$保持不变。
因此,一个$k$帧的视频可以由控制点表示为
$$Z=\{P^j\}_{j=1}^k\in\mathbb{R}^{Nk\times 2}$$
令$P^{init}$表示初始草图。将$P^{init}$重复$k$次作为$k$帧视频的初始化$Z^{init}$。 为了生成符合描述文本的视频,需要输出$\Delta Z=\{\Delta p_i^j\}_{i\in N}^{j\in k}$,即每一帧中每个控制点的偏移量。
模型框架
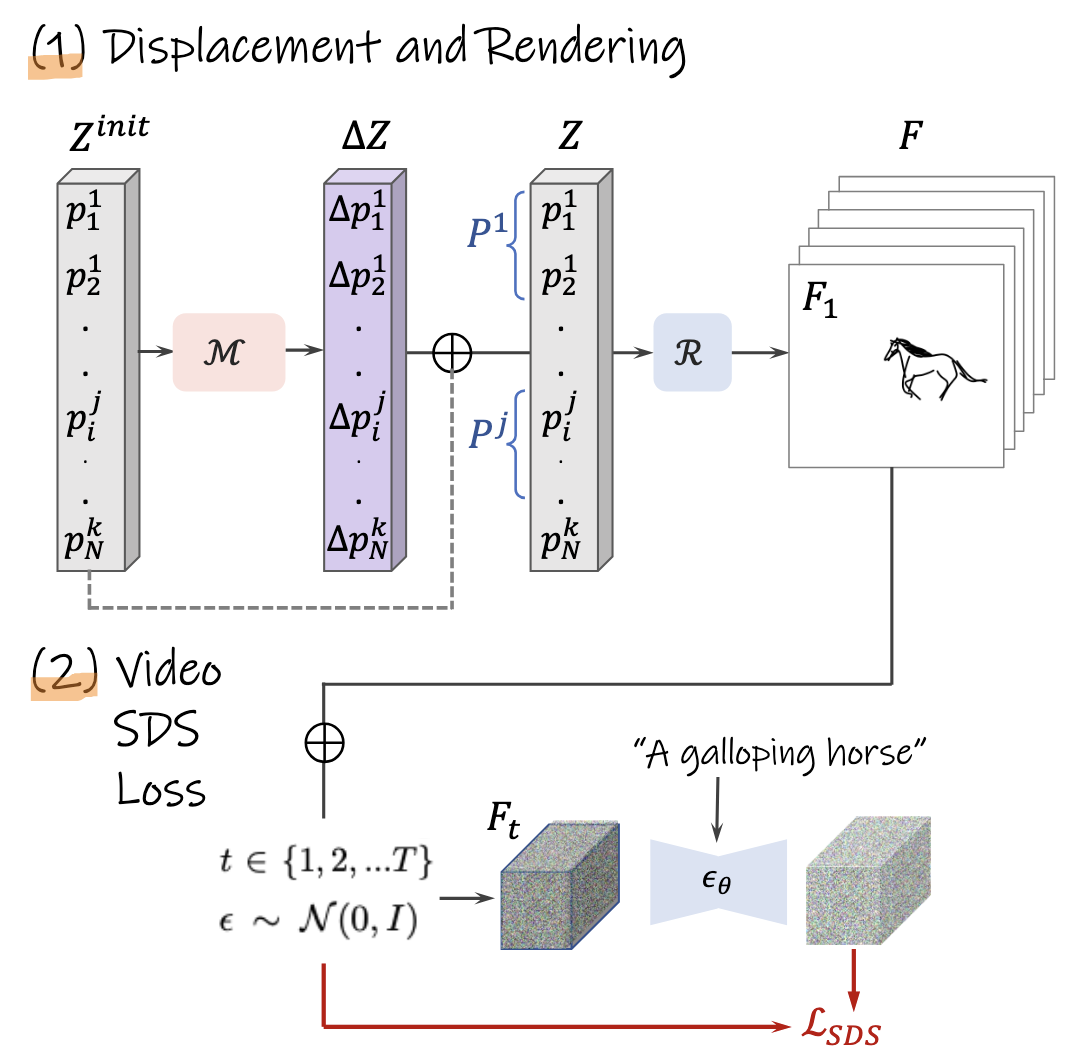
将$k$帧的所有控制点拼接在一起构成模型输入,经过一个小模型$\mathcal{M}$,得到每一帧中控制点的偏移量$\Delta Z$。接着,将$\Delta Z$与$Z^{init}$相加得到新的控制点序列$Z$。序列$Z$通过光栅器(rasterizer)$\mathcal{R}$得到像素图片序列。
将生成的视频和描述文本输入到预训练好的文生视频扩散模型。利用SDS损失函数,使生成的视频与描述文本相匹配。
$\mathcal{M}$的内部结构
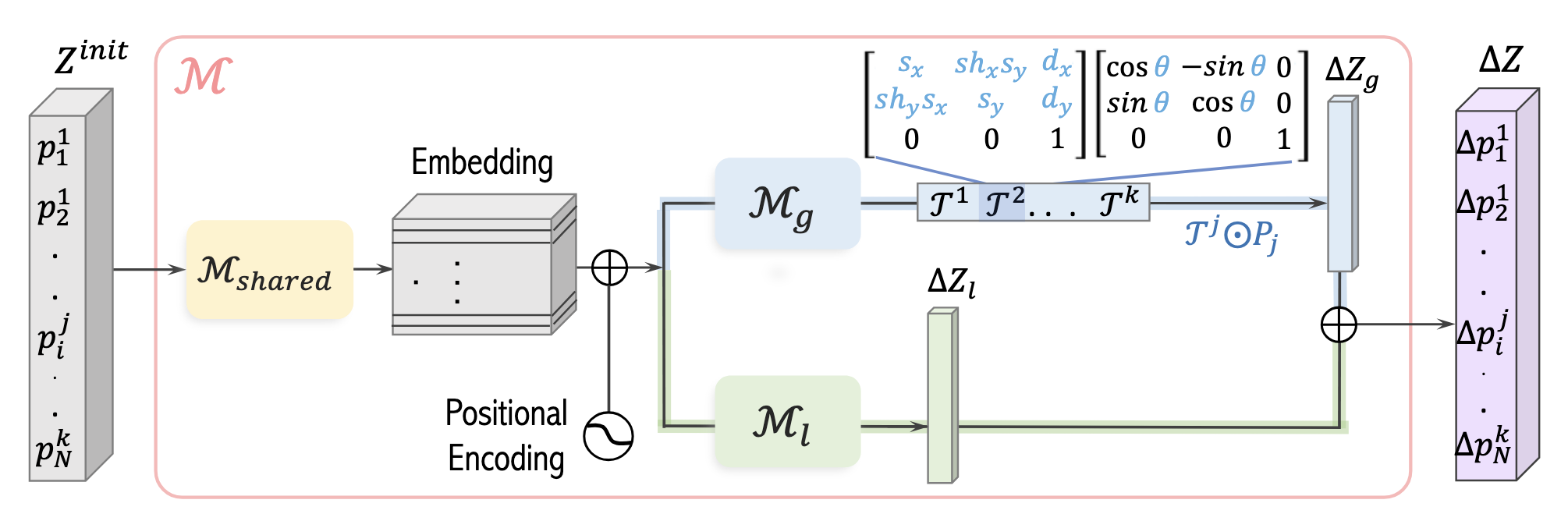
输入是初始化的控制点序列$Z^{init}$。首先通过一个骨架网络得到特征图(feature map)。接着,模型分成2支,分别学习局部信息和全局信息。对于局部信息,使用了简单的MLP;对于全局信息,对每个帧预测一个变换矩阵$\mathcal{T}^j$。变换包含缩放、剪切、旋转和平移。缩放、剪切和平移每种包含两个待预测的参数,旋转包含一个待预测的参数。基于$\mathcal{T}^j$得到每个点的全局偏移量:
$$\Delta p_{i,global}^j=\mathcal{T}^j\odot p_i^{init}-p_i^{init}$$
作者引入额外的超参数方便用户直接控制全局偏移量。对于平移、旋转、缩放和剪切分别引入超参$\lambda_t,\lambda_r,\lambda_s,\lambda_{sh}$。例如,假设模型预测平移参数为$(d_x^j,d_y^j)$,那么实际的平移参数为$(\lambda_td_x^j,\lambda_td_y^j)$。
最终的控制点偏移量是局部偏移和全局偏移的加和,即
$$\Delta Z=\Delta Z_l+\Delta Z_g$$
性能
论文汇报:在单张A100 GPU上生成1秒24帧的视频需要30分钟。
实测:在单张4090 GPU上生成1秒12帧的视频需要20分钟。