大语言模型火起来后,图机器学习社区的研究者也开始探究大语言模型在图数据上的可能应用。
Talk like a Graph: Encoding Graphs for Large Language Models
( Citation: Fatemi, Halcrow & al., 2023 Fatemi, B., Halcrow, J. & Perozzi, B. (2023). Talk like a Graph: Encoding Graphs for Large Language Models. https://doi.org/10.48550/arXiv.2310.04560 ) 研究了使用大语言模型解决简单图论问题的表现,包括了如下几个任务:
- 边查询:查询边在图中是否存在;
- 顶点度查询:计算指定顶点的度;
- 顶点个数查询:计算图中的顶点个数;
- 边个数查询:计算图中的边个数;
- 顶点连通性查询:查询与给定顶点连通的所有顶点;
- 环路查询:判断图中是否含有环路;
- 顶点不连通性查询:查询与给定顶点不连通的所有顶点。
这些任务极其简单,是更复杂问题的中间步骤。例如,要计算最短距离,首先要找到连通的顶点;要计算图中的社区,首先需要判断是否有环路;要搜索最具影响力的顶点,首先要计算顶点的度数。
本文考虑简单的图结构$G=(V,E)$,包括各种生成随机图的算法生成的图:
- Erdos-Renyi (ER) graphs
- Scale-free networks (SFN)
- Barabasi–Albert (BA) model
- stochastic block model (SBM)
- star graphs
- path graphs
- complete graphs
如下图所示。

为了使用语言模型解决图论问题,第一要把图结构编码为大语言模型的token序列,即用自然语言描述图;第二要选用合适的prompt提示方法向语言模型提问图论问题。
图结构编码的prompt提示方法
作者首先分别考虑如何用语言描述顶点和边,接着将它们结合起来描述图结构。
作者列出了5种描述顶点的语言:(n.1) 自然数;(n.2)广泛熟知的英文名字(如 David);(n.3)《权利的游戏》和《南方公园》电视节目中演员的名字;(n.4)美国政治家的名(first name);(n.5) 字母。
6种描述边的语言:(e.1)括号,即(起始顶点,终止顶点);(e.2)朋友,即两个端点是朋友;(e.3)合著者;(e.4)社交网络,即两个端点有联系;(e.5)箭头,即起始顶点$\to$终止顶点;(e.6)描述(incident),即直接描述起始顶点与终止顶点连接。
最终得到描述图结构的方法:
Adjacency:(n.1) + (e.1)
Incident: (n.1) + (e.6)
Friendship: (n.2) + (e.2)
Co-authorship: (n.2) + (e.3)
SP: (n.3,南方公园) + (e.2)
GOT: (n.3,权利的游戏) + (e.2)
Social Network: (n.2) + (e.4)
Politician: (n.4) + (e.4)
Expert: (n.5) + (e.5),该方法开头先说”你是个图分析师“(You are a graph analyst)。
具体的描述图结构的例子可以参加论文附录A.1。
提问问题的prompt提示方法
作者列举并验证了5种提问时的prompt方法:
- Zero-shot prompting(Zero-shot): 直接给出问题描述;
- Few-shot prompting(Few-shot): 先给出相关的例子,再描述问题;
- Chain-of-thought(CoT): 先给出相关的例子,在例子中展示如何一步一步地解决问题,再描述问题;
- Zero-shot CoT(Zero-CoT): 先说”Let’s think step by step“,再描述问题;
- Bag prompting(CoT-Bag): 特定于图问题的prompt方法。先说”Let’s construct a graph with the nodes and edges first“,再描述图结构,再描述问题。
除此之外,作者额外考虑描述问题的两种方式:(1)graph question encoder: 直接提问,如(“What’s the degree of node i?");(2)application question encoder: 使用实际场景中的词语提问,如查询顶点度的问题变成(“counting the number of friends for an individual”)。
实验结论
- 大语言模型在这些简单图论问题上的表现仍然较差;
- 描述图结构的方法对效果影响很大;
- 模型的参数量对效果影响很大。
Label-free Node Classification on Graphs with Large Language Models (LLMs)
( Citation: Chen, Mao & al., 2023 Chen, Z., Mao, H., Wen, H., Han, H., Jin, W., Zhang, H., Liu, H. & Tang, J. (2023). Label-free Node Classification on Graphs with Large Language Models (LLMS). https://doi.org/10.48550/arXiv.2310.04668 ) 研究了使用大语言模型为图节点打标签的可能性。GNN图节点分类通常需要高质量的标签,人工取得标签是昂贵的,而大模型在零样本和少样本学习任务上取得不错的效果。因此,作者考虑两个问题:(1)设计合适的prompt提示,使大模型输出准确的标签;(2)使用GNN训练时,选取同时具有高质量标签和代表性的节点作为训练集。
本文的只考虑具有文本节点属性的图数据,即Cora, Citeseer, PubMed, OGBN-Arxiv, OGBN-Products, WikiCS。具体来说,图$G_T=(V,A,T,X)$,其中$n$个节点$V=\{v_1,\cdots,v_n\}$关联着原始属性$T=\{\pmb{t}_1,\cdots,\pmb{t}_n\}$,原始文本属性可以编码为句子表征$X=\{\pmb{x}_1,\cdots,\pmb{x}_n\}$。$A$表示邻接矩阵。
鉴于标注工作的昂贵,本文提出LLM-GNN,即使用LLM进行标定,包括如下4步:
- 标注节点选择
- LLM标定
- 后处理
- GNN训练和预测
如下图所示。
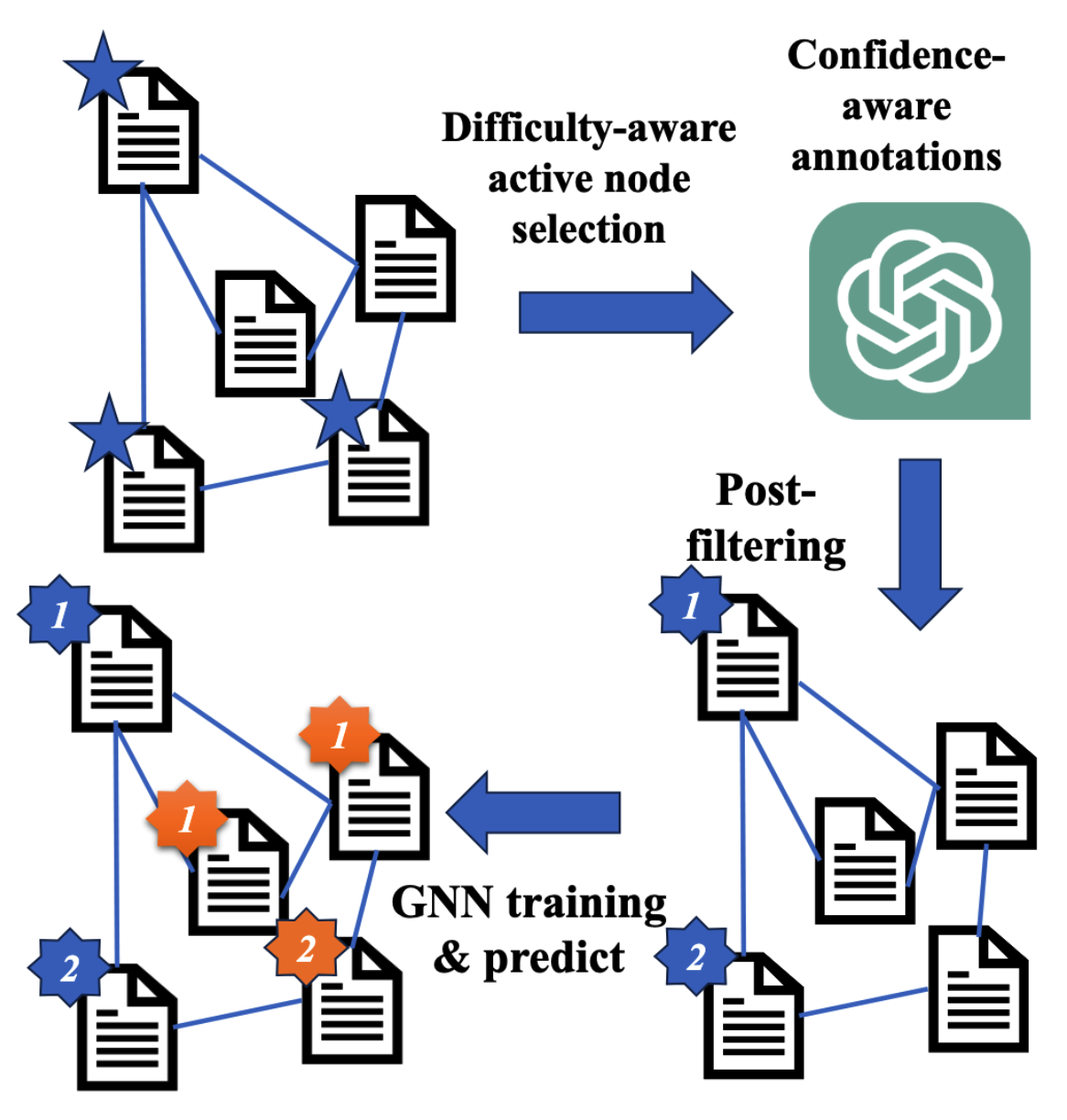
标定节点选择
作者发现,在多个图数据集上,距离KMeans聚类中心越近的顶点,使用LLM标定的准确率越高。如下图所示。作者随机采样1000个顶点,按它们距离KMeans聚类中心的距离划分为10组,分别计算标定准确率。图中蓝线表示前$i$组的平均准确率。可以看到随着组号增大(即距离增大)准确率呈下降趋势。
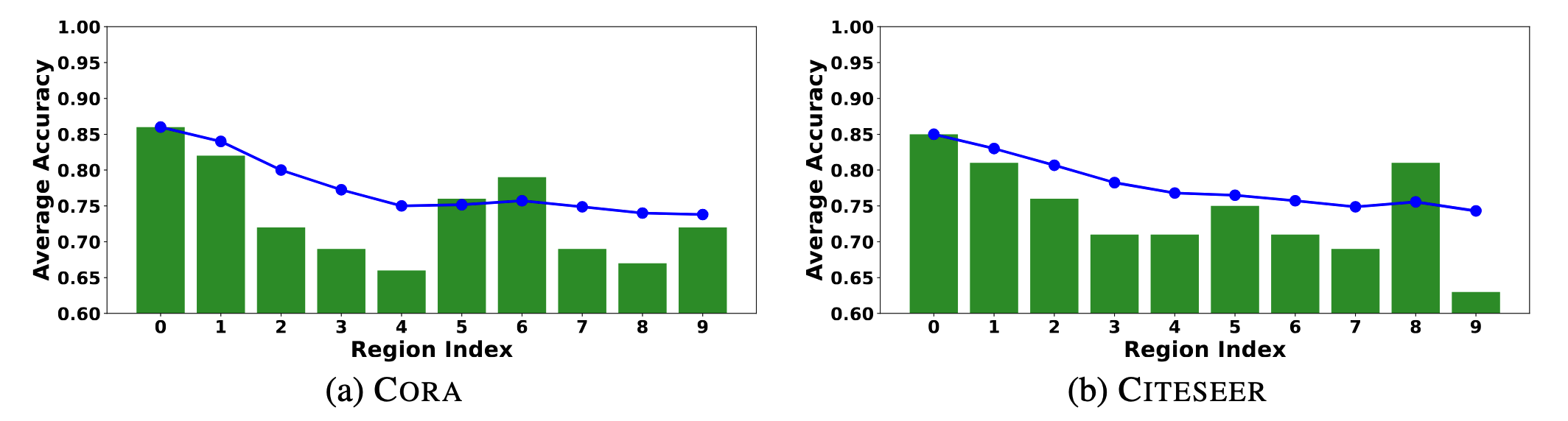
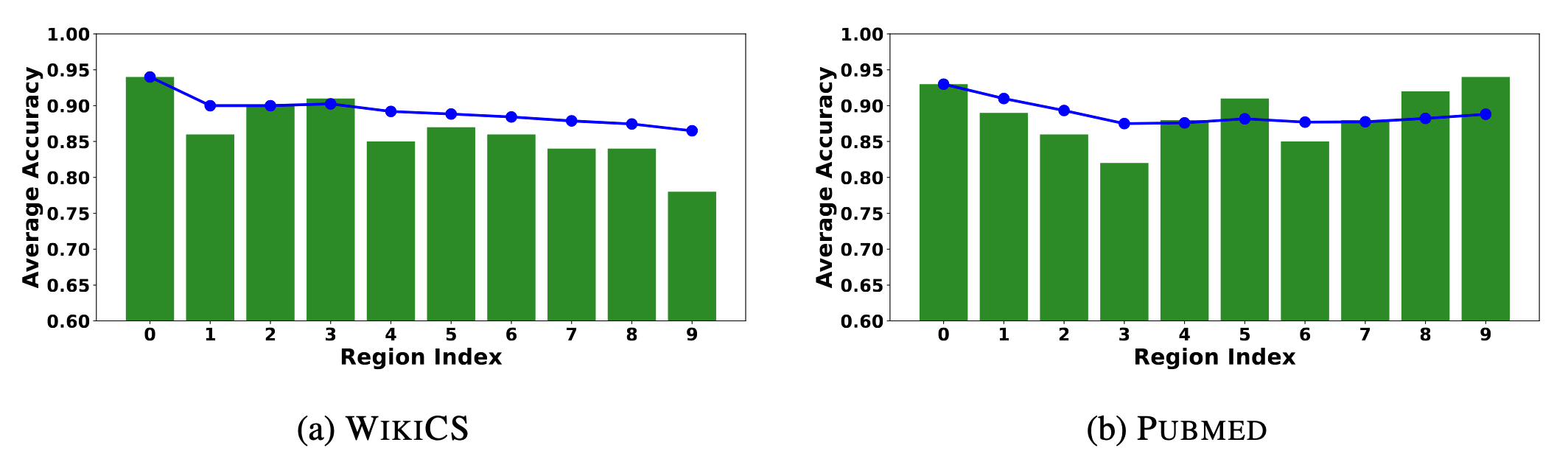
作者定义了一个参量衡量到聚类中心的距离:
$$\text{C-Density}(v_i)=\frac{1}{1+\parallel x_{v_i}-x_{\text{CC}_{v_i}}\parallel}$$
其中$\text{CC}_{v_i}$表示$v_i$所在的聚类的中心。
传统的”主动“(active)标定节点选择方法主要考虑节点的多样性和代表性,一般可选用PageRank分数衡量结构多样性。这里为了结合C-Density,考虑两种分数对应排名的加权和:
$$f(v_i)=\alpha_0\times r_{act}(v_i)+\alpha_1\times r_{\text{C-Density}}(v_i)$$
其中$r_{\star}$表示排名。选取$f_{v_i}$较高的顶点作为待标定节点集。
带有置信度的标定
使用LLM标定时,作者希望同时得到一个置信度分数,来更好地衡量标注的可靠性。作者列举了5种从LLM得到置信度的方法:
- 直接询问置信度
- 带有推理方法的prompt指示,如chain-of-thought和multi-step reasoning
- TopK prompt,即命令LLM生成K个最可能的答案,选择可能性最高的作为结果
- 多次询问LLM同一个问题,选择重复次数最多的答案
- 混合方法,即(3)和(4)
作者在上述prompt问题前添加了供LLM in-context learning的例子,为了效率本文每次只使用一个例子。如下图所示。

接着,作者通过实验验证标定的准确性和可靠性,即(1)采样100个标定的顶点,直接比较标定结果和真实标签,计算准确率;(2)考察LLM输出置信度和准确率的关系。随机采样300个顶点,将它们按置信度从大到小排序,计算前$k$个顶点的平均标定准确率,其中$k=\{50,100,150,200,250,300\}$。结果如下图所示。
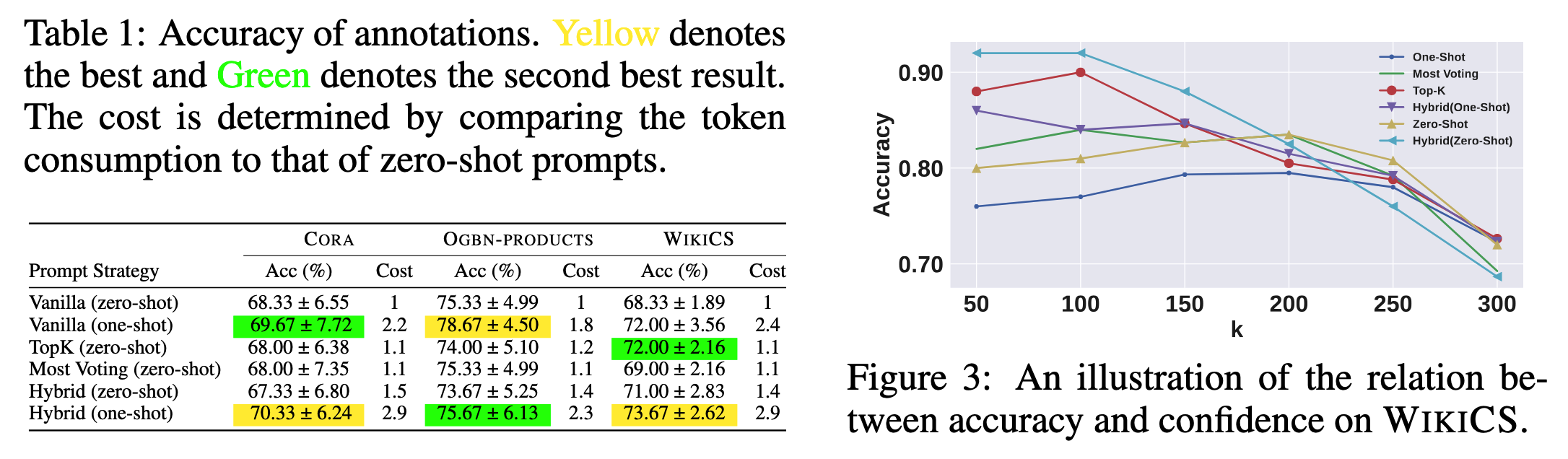
作者根据结果给出3个发现:
- LLM在zero-shot(不提供例子的prompt)的条件下效果良好,表明LLM是好用的标定工具
- LLM在few-shot的条件下标定准确率有轻微的提升
- zero-shot的混合prompt提示方法是最高效的方法,因为LLM输出的置信度可以较准确得表明标定的质量
作者在后续实验中均使用zero-shot的混合prompt提示方法。
标定后处理
在后处理步骤,我们已经得到LLM的标定结果,因此可以用标定结果直接计算标签的多样性。后处理的目的是删除低质量的标定节点,缩小标定集,保证标签的多样性。作者通过熵定义了一个参量:
$$\text{COE}(v_i)=H(y_{V-\{v_i\}})-H(y_{V})$$
即考察删除节点$v_i$后熵的变化。作者认为应该删除COE值较大的顶点。作者同时结合了LLM输出的置信度共同评估标签的质量,即计算加权和:
$$f(v_i)=\beta_0\times r_{\text{conf}}(v_i)+\beta_1\times r_{\text{COE}}(v_i)$$
其中$r_{\star}$表示排名。 不断删除顶点直到达到预设的标定集规模。
作者的说明
作者发现同时使用本文提出的标定节点选择方法和后处理方法并不能取得最优的结果,因此可以将传统的节点选择方法与本文提出的后处理方法结合。作者强调他们提出的是一个管线,管线内部可以灵活替换。
数据集和实验设置
本文使用4个引文数据集,1个网页数据集,1个产品关联性数据集(产品同时购买关系)。数据集信息如下所示。
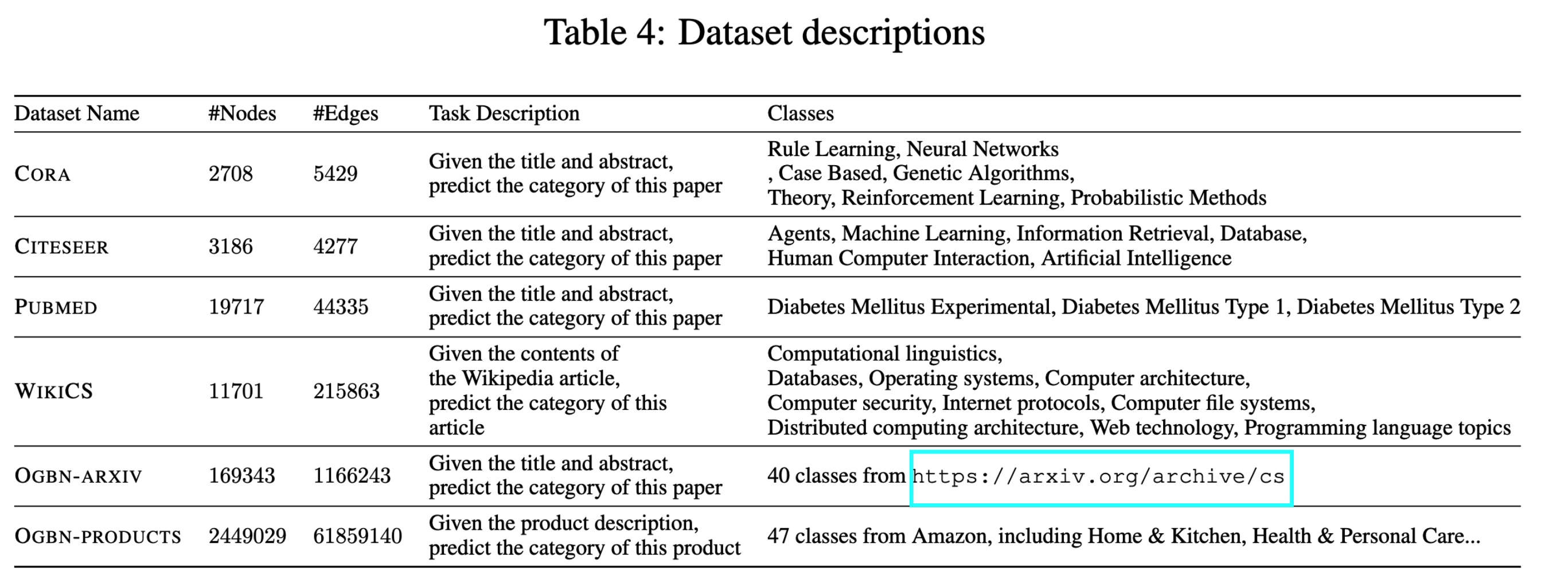
本文采用节点分类任务。作者为每个节点类选取20个顶点进行标定。模型使用GCN和GraphSAGE。作者强调没有对$\alpha_0,\alpha_1,\beta_0,\beta_1$进行调参。 训练GNN时,没有划分验证集,每组实验重复3次。中小数据集训练30 epochs,大数据集训练50 epochs。作者认为本文中的训练标签是带有噪声的,训练小代数是防止GNN对噪声过拟合,可以视作一种early stopping策略。
LLM使用GPT-3.5-turbo-0613。
实验结果
标定节点选择方法对比
本文中的标定节点选择方法涉及到主动学习方法,对比时也考虑了主动学习的已有方法。对比方法包括4类:
- 传统方法,包括Random, Density-based, GraphPart, FeatProp, Degree-based, Pagerankcentrality-based, AGE, RIM
- C-Density方法及其与传统方法的结合,记为DA-
- 后处理方法,记为PS-
- C-Density与后处理的结合,记为PS-DA
实验结果如下图所示。
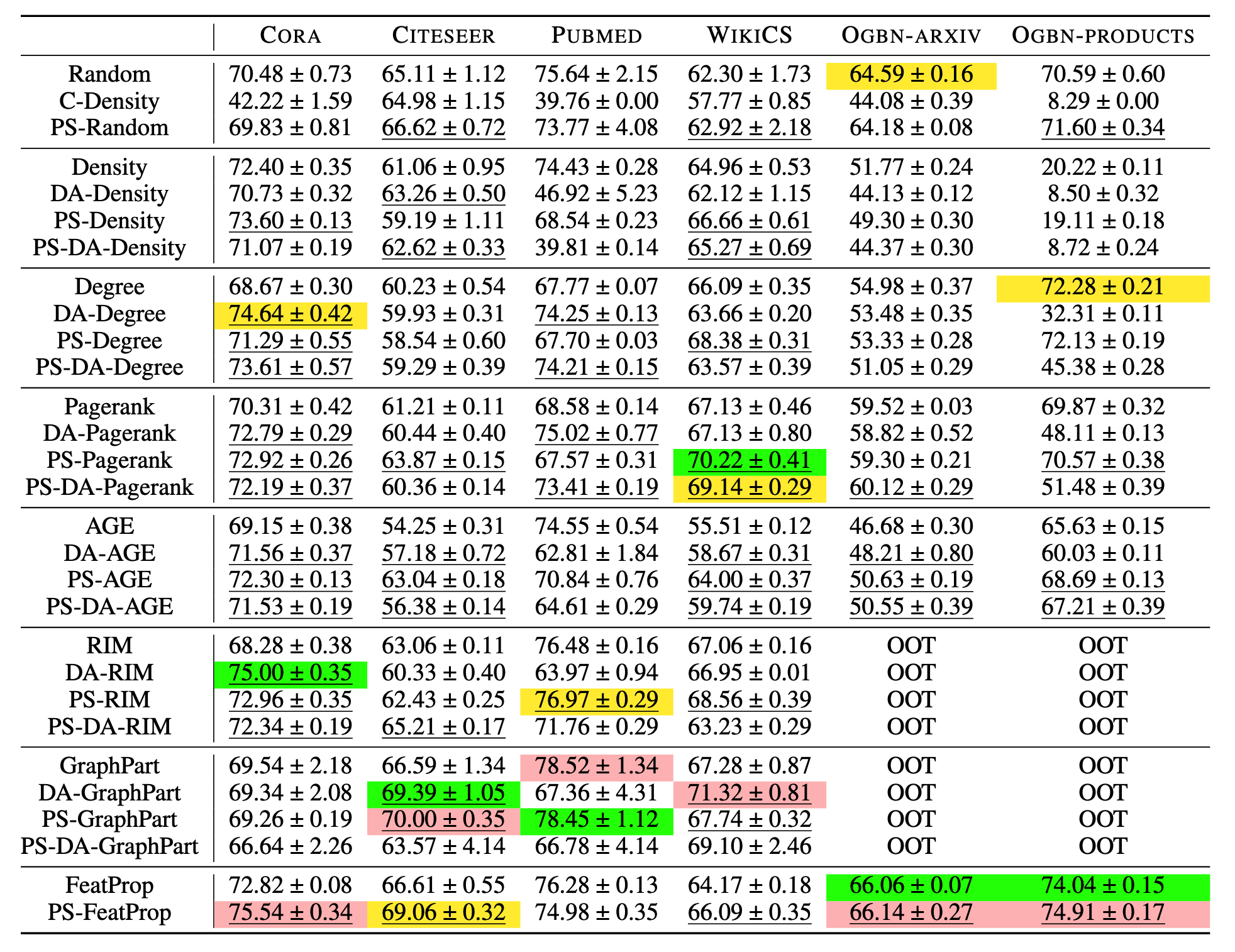
根据结果作者给出3点发现:
- 后处理方法是很有效的
- C-Density方法虽然得到的标定准确率高,但会导致标签不平衡问题。例如,作者发现在PubMed数据集上它选择的所有标定节点有相同的标签
- 本文没有调参,展示的结果有上升空间
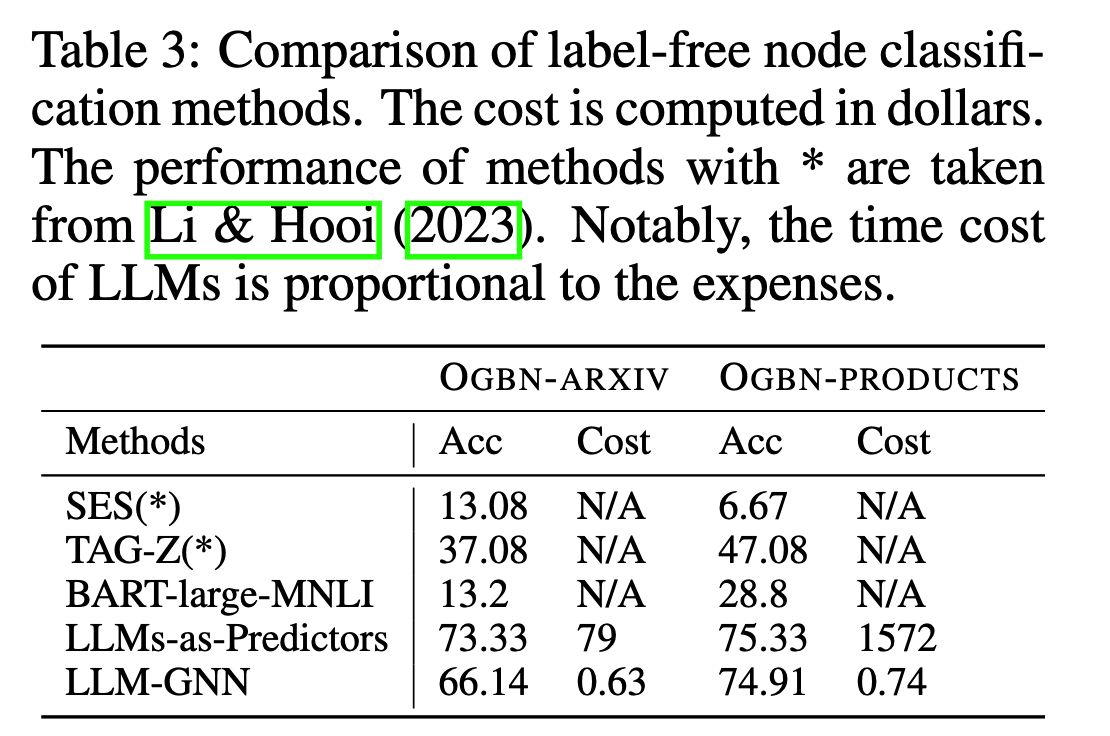
与无标签节点分类方法对比
作者展示了在两个OGBN大数据集上的节点分类准确率和花费,花费用美元dollar衡量。对比方法有3类:
- 零样本节点分类方法:SES, TAG-Z
- 零样本文本分类方法:BART-Large-MNLI
- 作者先前提出的使用LLM进行分类:LLMs-as-Predictors
结果如下图所示。可以看到本文的LLM-GNN的准确率显著由于零样本方法。LLMs-as-Predictors虽然准确率更高,但花费远超过使用LLM打标签的方法。
标定节点数量的影响
作者考察每个类标定节点的数量$B$对节点分类准确率的影响,考察$B=\{70,140,280,560,1120,2240\}$。结果如下图所示。
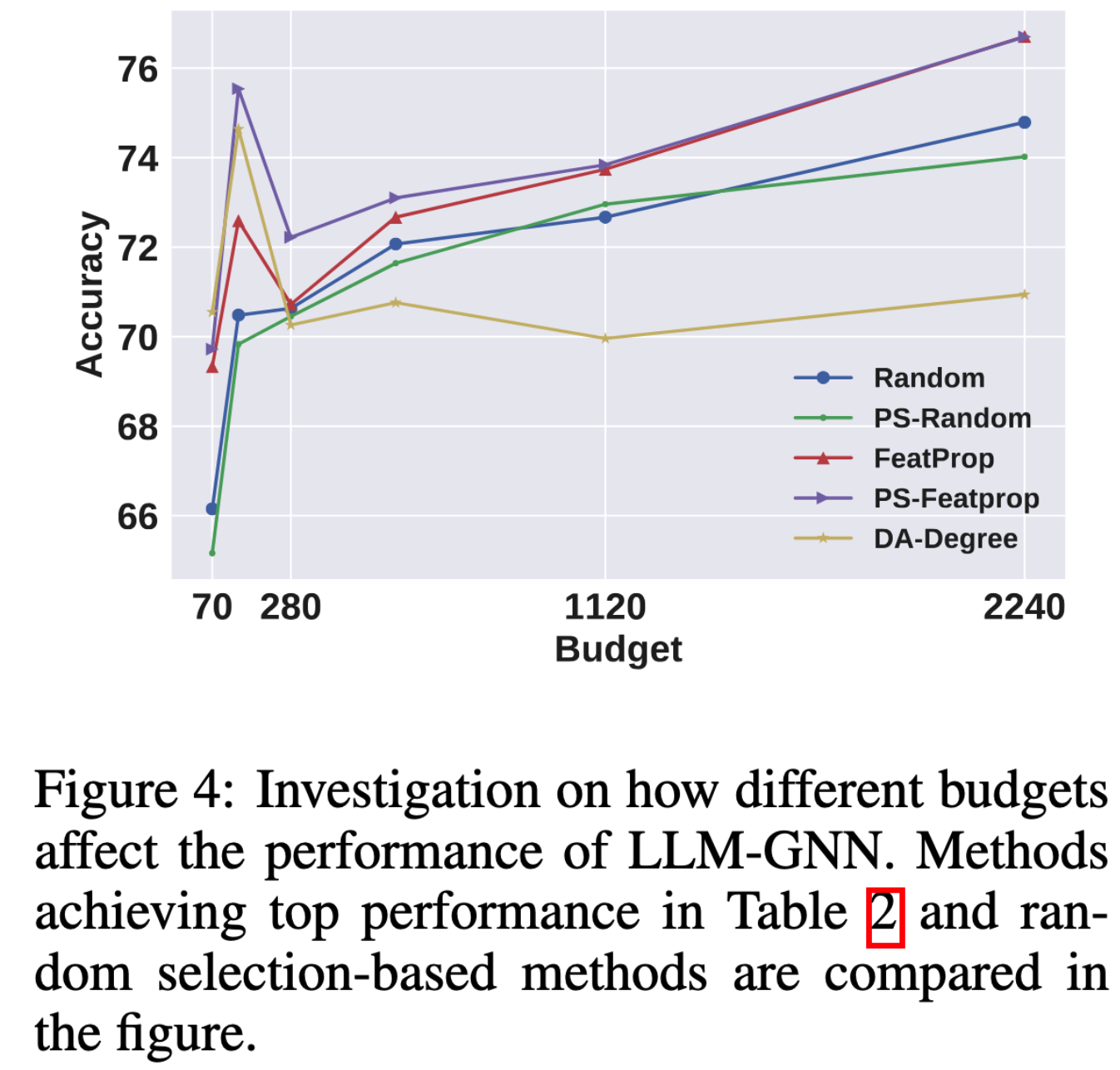
根据结果作者给出两点发现:(1)随着标定数量的提升,节点分类准确率逐渐上升;(2)由于LLM的标定有误差,节点分类准确率上升的速度受到限制,不如增加真实标签数量的上升速度。
LLM标定结果的性质
作者进一步研究LLM标定带来的噪声和人工加噪声的区别。假设LLM标定结果的准确率是$q\%$,作者构建另一组人工加噪声的标签,即随机选择$1-q\%$的标签进行扰动。观察训练节点分类器的结果。同时还考察一种对人工加噪声标签场景进行优化的训练策略RIM,观察其对LLM生成的标签是否有效。结果如下图所示。

根据结果作者给出两点发现:(1)LLM的标签噪声和人工加噪声是完全不同的。LLM标签不会像人工加噪声导致过拟合;(2)RIM对LLM标签几乎无效。
相关工作
图上的主动学习
图主动学习的目的是在给定每个类的标定数量的条件下,选取真正的标定节点,以最大化测试集上的准确率。有两类现有工作。第一类基于一些对标签代表性和多样性的假设,如 ( Citation: Ma, Ma & al., 2023 Ma, J., Ma, Z., Chai, J. & Mei, Q. (2023). Partition-Based Active Learning for Graph Neural Networks. https://doi.org/10.48550/arXiv.2201.09391 ) 假设多样性和节点的划分(聚类)有关,因此标定节点从不同的聚类选择; ( Citation: Zhang, Yang & al., 2021 Zhang, W., Yang, Z., Wang, Y., Shen, Y., Li, Y., Wang, L. & Cui, B. (2021). GRAIN: improving data efficiency of graph neural networks via diversified influence maximization. Proceedings of the VLDB Endowment, 14(11). 2473–2482. https://doi.org/10.14778/3476249.3476295 ) 假设代表性和节点的影响力有关,因此选择影响力分数高的节点作为标定节点。另一类方法直接使用训练模型的准确率作为目标,使用强化学习方法选择标定节点。
Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs
( Citation: Chen, Mao & al., 2023 Chen, Z., Mao, H., Li, H., Jin, W., Wen, H., Wei, X., Wang, S., Yin, D., Fan, W., Liu, H. & Tang, J. (2023). Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs. https://doi.org/10.48550/arXiv.2307.03393 ) 与第二篇来自于同一个第一作者,调研大语言模型在文本属性图学习上的应用,专注于节点分类任务。 作者分别讨论LLM的两种可能用法:
- LLM-as-Enhancers: 将LLM作为文本属性的增强器(预处理器),由GNN在增强的数据上训练和预测
- LLM-as-Predictors: 将LLM作为节点分类器,前提是将图的结构和属性信息通过自然语言提供给LLM
传统的将文本转化为节点属性向量的方法有独热编码和Word2vec等,这类简单的缺少语义信息的表征方法难以表征多义词,并且缺乏语义信息。LLM能够很好地理解语义信息。因此可以考虑用LLM增强文本属性。另一方面,LLM在一些具有隐式图结构的具体任务上有较好的表现,如推荐系统、排名、多步推理等。因此也可以考虑直接用LLM执行节点分类任务。
本文考虑的文本属性图(text-attributed graphs, TAG)定义为$G=(V,E,A,S)$,每个顶点$v_i$关联文本属性$\pmb{s}_i$。 节点分类任务是指给定一组带标签的节点,预测其他无标签的顶点的类别标签。
针对LLM作者将它们分成两类,即表征可见和表征不可见的LLM:
表征可见LLM:即用户可以得到单词、句子、段落的表征向量,典型的模型有BERT, Sentence-BERT, Deberta。
表征不可见LLM:即黑盒大模型,通常只提供网页服务或有限的API,如ChatGPT。
更详细地,可将LLM分成3类:
预训练LM(PLMs):指规模较小的预训练语言模型,如Bert, Deberta,通常需要对下游任务进行微调。
句子表征模型:这类模型使用PLMs作为基础编码器,并采用双编码器结构,使用有监督或者对比学习进一步预训练,通常不需要对下游任务进行微调。包括开源的离线模型,如Sentence-BERT,和黑盒的在线模型,如OpenAI的text-ada-embedding-002。
LLMs:分为开源模型,如LLaMA,和黑盒模型,如ChatGPT, GPT-4。
LLM作为增强器
待补充内容…
LLM作为分类器
作者探索了两种可能的分类方式,一是忽略图结构,只使用节点的文本属性对节点分类;二是加入图结构。
只使用节点属性进行文本分类
作者使用ChatGPT(GPT-3.5-turbo-0613)作为LLM。数据集包括Cora, Citeseer, PubMed, OGBN-Arxiv, OGBN-Products,即4个引文数据集和1个商品同时购买关系数据集。考虑到LLM的费用,作者只对每个数据集随机选取200个节点作为测试集,并对所有的实验重复2次。
作者列举了4种prompt提示方法:
- 零样本提示
- 少样本提示
- 带CoT的零样本提示
- 带CoT的少样本提示
实验结果如下图所示。
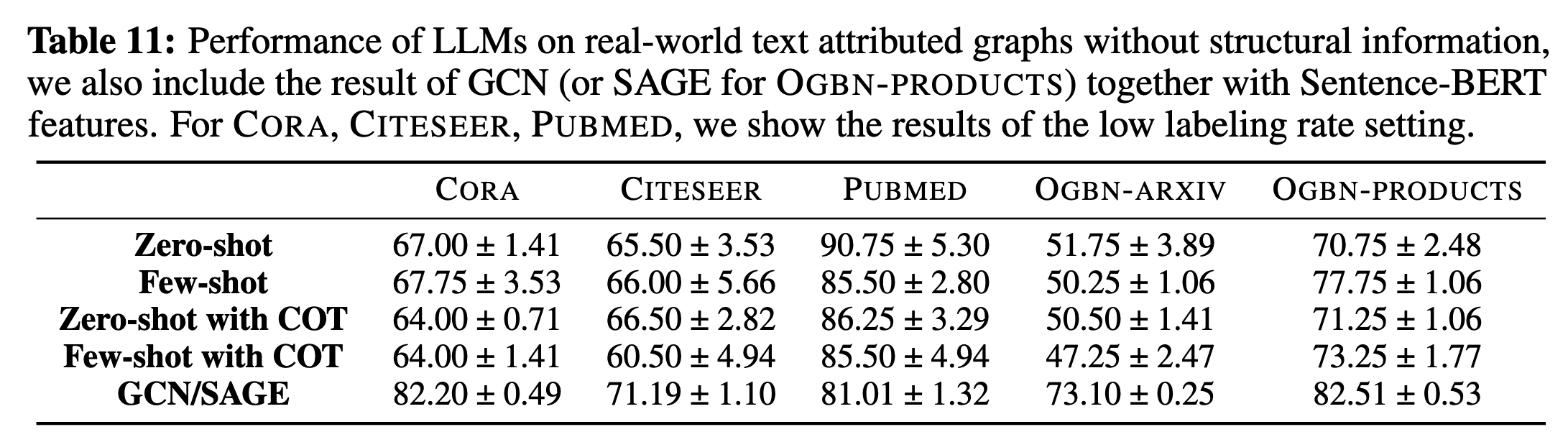
根据结果,作者给出4点发现:
- LLMs在一些数据集上表现较好,如PubMed。对于为什么在Cora, Citeseer上比不过GNN,需要进一步研究。
- LLMs一些错误的预测也是有道理的。在引文数据集上,一篇论文可以有多个类别,而数据集只选择其中一个作为标签(ground truth),但其实LLM的预测是对的。

- CoT没有用
- LLM中可能存在测试数据的泄露
在OGBN-Arxiv引文数据集上,作者发现对计算机类论文使用一种特殊标签命名,可以显著提高LLM的预测准确率,怀疑是这种微小的改动唤醒了LLM的”记忆“。具体来说,作者试验了3种标签命名法: (1)使用Arxiv的原生命名,如”arxiv cs.CV“;(2)使用自然语言,如"computer vision”;(3)使用特殊的命名,即"arxiv cs subcategory"。结果显示第(3)种的准确率显著高于前两个,如下图所示:

加入图结构信息进行图节点分类
待补充内容…
GraphGPT: Graph Instruction Tuning for Large Language Models
( Citation: Tang, Yang & al., 2023 Tang, J., Yang, Y., Wei, W., Shi, L., Su, L., Cheng, S., Yin, D. & Huang, C. (2023). GraphGPT: Graph Instruction Tuning for Large Language Models. https://doi.org/10.48550/ARXIV.2310.13023 ) 研究了构建对于不同图数据集和下游任务通用的图大模型。作者指出现有的自监督方法在生成节点表征后,仍然需要下游任务的标签做进一步微调,这限制了它们的泛化能力,因为高质量标签的获取是昂贵的(例如,推荐系统的冷启动,在新城市的交通流预测等)。受启发于大语言模型优秀的泛化性和零样本学习能力,本文设计了针对图结构的指令微调技术,对大语言模型进行微调。
作者使用预测论文类别作为例子,说明问题的挑战性,对比了3种方法。(a) 将论文的标题和摘要文本作为prompt; (b) 使用现有工作 ( Citation: Chen, Mao & al., 2023 Chen, Z., Mao, H., Li, H., Jin, W., Wen, H., Wei, X., Wang, S., Yin, D., Fan, W., Liu, H. & Tang, J. (2023). Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs. https://doi.org/10.48550/arXiv.2307.03393 ) 提供的prompt; (c) 使用本文微调的大模型。(b)的一个关键缺点是显著增大了token数目,容易受限于大模型的token限制。在这个例子中,只有本文的(c)预测正确论文的类别。

本文在写作时没有注意对第一次出现的名词进行解释,如"graph token"。一些技术要点也没有详细阐述。
解决方案 – GraphGPT
将图结构编码和语言编码对齐
作者使用图编码器将顶点映射到向量,使用文本编码器将描述顶点的文本映射到向量。
两阶段指令微调
作者先使用“图匹配”无监督任务对新加的投射层进行微调,冻结LLM和图编码器的参数。投射层可以是简单的1层线性层。 对于图中的每个顶点,随机采样$h$-跳的邻居构成子图。
待补充内容…
作者接着使用下游任务对新加的投射层进行微调,仍然冻结LLM和图编码器的参数。采样子图和prompt的策略相同,只是将问题替换为对应的下游任务,如节点分类、链路预测等。
加入链式思考(chain-of-thought, CoT)
作者设计了CoT prompt。
实验 – GraphGPT
本文的实验数据集完全采用了引文数据集,即OGB-ArXiv, PubMed和Cora。
Unifying Large Language Models and Knowledge Graphs: A Roadmap
( Citation: Pan, Luo & al., 2023 Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J. & Wu, X. (2023). Unifying Large Language Models and Knowledge Graphs: A Roadmap. https://doi.org/10.48550/arXiv.2306.08302 ) 是一篇关于大语言模型和知识图谱的综述,讨论了3个问题:
- 使用知识图谱加强LLM
- 使用LLM对知识图谱数据增强
- 协同LLM和知识图谱
One for All: Towards Training One Graph Model for All Classification Tasks
( Citation: Liu, Feng & al., 2023 Liu, H., Feng, J., Kong, L., Liang, N., Tao, D., Chen, Y. & Zhang, M. (2023). One for All: Towards Training One Graph Model for All Classification Tasks. https://doi.org/10.48550/arXiv.2310.00149 ) 提出并研究训练一个通用图分类(包括顶点、边、图级别)模型的问题。