本文致力于梳理常见的图节点编码器,包括较早的DeepWalk, Node2vec以及各种经典的图神经网络。
DeepWalk: Online Learning of Social Representations
( Citation: Perozzi, Al-Rfou & al., 2014 Perozzi, B., Al-Rfou, R. & Skiena, S. (2014). DeepWalk: Online Learning of Social Representations. https://doi.org/10.1145/2623330.2623732 ) 提出了DeepWalk。
相关定义和记号
给定图$G=(V,E)$,以及其对应的标记图$G_L=(V,E,X,Y)$,其中$X\in \mathbb{R}^{|V|\times S}$表示初始属性矩阵,$Y\in\mathbb{R}^{|V|\times |Y|}$表示节点的标签矩阵。表征学习的目标是得到低维表征矩阵$X_E\in\mathbb{R}^{|V|\times d}$,其中$d<S$,使得表征向量具有如下性质:
- 适应性(Adaptability):真实的社交网络可能是不断变化的,在图中插入新的边时不应当重新执行表征算法;
- 反映社区结构(Community Aware)
- 低维(Low Dimentional)
- 连续(Continuous):表征空间是连续空间,即每个元素是实数。
随机游走(Random Walk)
将从节点$v_i$开始的游走路径记为$W_{v_i}$,整条路径可以表示为
$$W_{v_i}={W_{v_i}^1, W_{v_i}^2, \cdots, W_{v_i}^k, W_{v_i}^{k+1}, \cdots}$$ 其中$W_{v_i}^{k+1}$为随机挑选的节点$W_{v_i}^k$的邻居。 随机游走方法已被应用于内容推荐问题和社区发现问题中( ( Citation: Reid, Fan & al., Reid, A., Fan, C. & Kevin, L. (s.d.). Retrieved from https://ieeexplore.ieee.org/document/4031383/ ) ,GraphMAE2用了该聚类方法)。
随机游走访问局部信息。使用随机游走有两大好处。一是易并行化,二是修改图结构时不需要重新运行全部算法。
幂律分布(Power Low)
幂律分布的密度函数如下:
$$f(x)=ax^{-k}$$
幂律分布是长尾的,并且是尺度无关的。如果在画幂律分布时将X-Y坐标系都取log,那么密度曲线将成为直线。通过简单地推导可以得出幂律分布是唯一具有尺度无关性质的分布。
作者发现如果网络中的顶点度符合幂律分布,那么顶点出现在随机游走路径中的频率也符合幂律分布,这一现象与单词在句子中出现的频率分布相像。这启发作者将NLP中的表征方法迁移到图表征中来。

文本表征学习
DeepWalk的解决方案
DeepWalk将节点看作单词,通过随机游走形成句子。接着调用文本表征方法word2vec得到节点的表征向量。
node2vec: Scalable Feature Learning for Networks
( Citation: Grover & Leskovec, 2016 Grover, A. & Leskovec, J. (2016). node2vec: Scalable Feature Learning for Networks. https://doi.org/10.48550/arXiv.1607.00653 ) 提出了Node2vec,仍然基于随机游走的图表征方法。它相比于DeepWalk更加细致地设计了生成游走路线的方案。
Node2vec的动机
随机游走是深度优先的图遍历策略,那么广度优先搜索是否可行呢?答案是肯定的。深度优先时考虑的是社区节点内部的相似性,而广度优先考虑的是邻居结构的相似性,如下图中的$u,s_6$两个节点。结构相似的两个节点可以相似很远,但它们的局部子图具有一定的相似性。
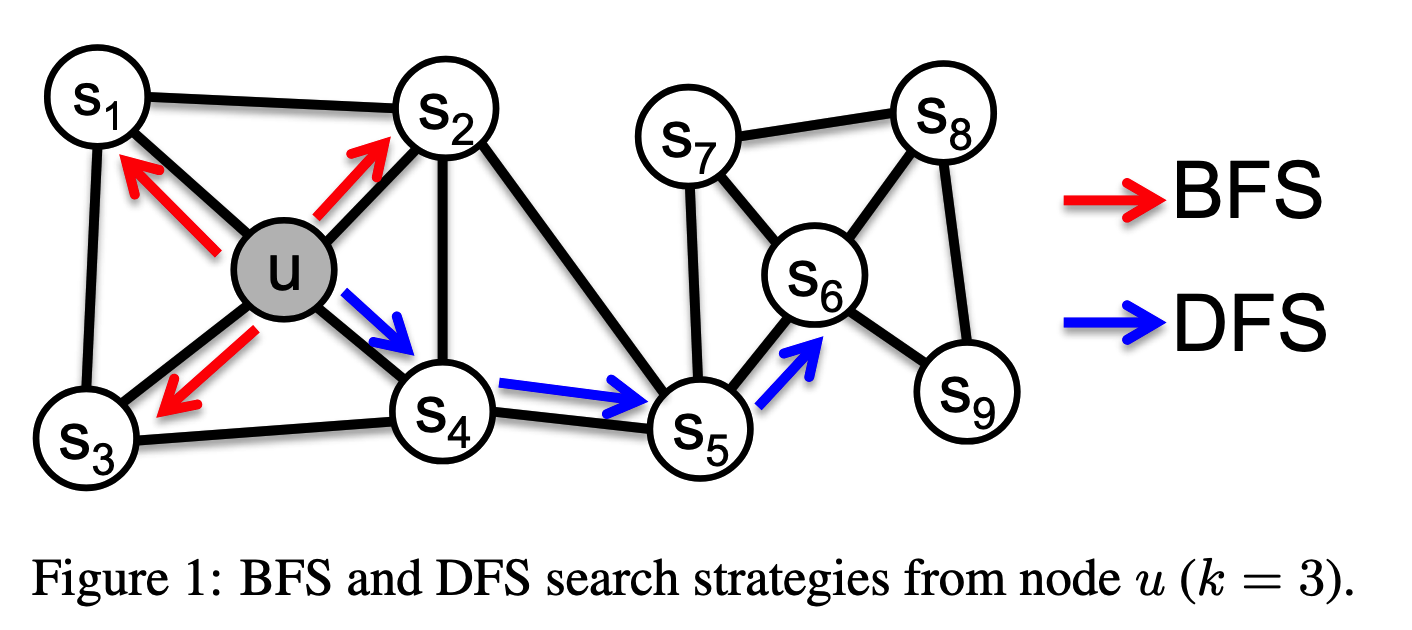
新的游走方案
与完全随机的深度优先游走不同,作者认为图中社区内部的相似性和节点之间的结构相似性是混合存在的。因此node2vec提供了带偏好的游走方案:
当游走从节点$t$走到节点$x$,准备决定下一步时: $$ \alpha_{pq}(t,x)=\left. \begin{cases} \frac{1}{p}, & \text{if } d_{tx}=0 \\ 1, & \text{if } d_{tx}=1 \\ \frac{1}{q}, & \text{if } d_{tx}=2 \end{cases} \right. $$ 其中$d_{tx}$表示节点$t,x$之间的最短路径长度。最终游走的概率(未归一化)为$\pi(t,x)=\alpha_{pq}(t,x)\cdot w_{vx}$,其中$w_{vx}$表示边权。
当$q>1$时,倾向于访问更近的节点,即广度优先的游走;反之当$q<1$时,倾向于访问更远的节点,即深度优先的游走。
GCN: Semi-supervised Classification with Graph Convolutional Networks
( Citation: Kipf & Welling, 2017 Kipf, T. & Welling, M. (2017). Semi-Supervised Classification with Graph Convolutional Networks. https://doi.org/10.48550/arXiv.1609.02907 ) 提出了图卷积网络。
图卷积
图卷积层使用了一种”消息传递“机制,在每一层,将前一层的一阶邻居顶点的表征聚合到当前顶点。
$$ \begin{align} H^{(l+1)} &=\sigma(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}H^{(l)}W^{(l)}) \\ h^{(l+1)}_i &=\sum_{j=1}^n\frac{a_{ij}}{\sqrt{\tilde{d}_i\tilde{d}_j}}h_j^{(l)} \\ \end{align} $$ 其中$\tilde{A}=A+I_N$,$\tilde{D}_{ii}=\sum_j\tilde{A}_{ij}$表示度矩阵。$W\in\mathbb{R}^{n\times d}$是可训练的矩阵,它的主要作用是对表征向量降维。
从谱域理解图卷积
GCN的消息传递表达式容易理解,但是针对这样的设计最好要有理论解释。GCN利用图信号处理对它的设计做理论解释。
图的拉普拉斯矩阵
低通滤波器和图卷积
从信号处理的角度,将图的属性向量$x$的任意维度视为信号(signal)。那么,给定滤波器$g$,图卷积操作被定义为
$$x*g=Ug_{\theta}U^Tx$$ 其中$g_{\theta}=diag(U^Tg)$是对角矩阵。所有的谱域GNN都采用该卷积操作的定义。不同的是对于$g_{\theta}$的选择。
- Spectral GNN将$g_{\theta}$定义为完全可训练的对角矩阵。但是由于矩阵的特征分解需要$O(n^3)$的时间,因此是不可扩展的。
- ChebNet使用Chebyshev多项式对$g_{\theta}$进行近似。
$$ \begin{align} g_{\theta}&=\sum_{i=1}^K\theta_iT(\tilde{\Lambda}) \\ \tilde{\Lambda}&=\frac{2\Lambda}{\Lambda_{max}}-I_n \\ T_i(x)&=2xT_{i-1}(x)-T_{i-2}(x) \\ T_0(x)&=1 \\ T_1(x)&=x \\ \end{align} $$
其中容易推导$\tilde{\Lambda}\in[-1,1]$。基于Chebyshev多项式,图卷积操作成为
$$x*g=\sum_{i=0}^K\theta_iT_i(\tilde{L})x$$
- 现时流行的图卷积网络(Graph Convolutional Network, GCN)基于ChebNet做了进一步简化:
$$ \begin{align} K&=1 \\ \lambda_{max}&=2 \\ \theta&=\theta_0=-\theta_1 \\ \end{align} $$
这样图卷积操作成为
$$x*g=\theta(I_n+D^{-1/2}AD^{-1/2})x$$
实际应用中,$I_n+D^{-1/2}AD^{-1/2}$会导致算术不稳定,因此GCN使用$\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}$进行替换。
GAT: Graph Attention Networks
( Citation: Veličković, Cucurull & al., 2018 Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P. & Bengio, Y. (2018). Graph Attention Networks. https://doi.org/10.48550/arXiv.1710.10903 ) 提出GAT, 在GCN的基础上添加可训练的attention权重。具体来说,GAT层的输入是节点的特征向量$h_i$,输出是聚合邻居信息后的节点特征向量$h_i’$.
$$h_i’=\sigma\left(\sum_{j\in\mathcal{N}_i}\alpha_{ij}Wh_j\right)\in\mathbb{R}^{2F’}$$
其中的权重$\alpha_{ij}\in\mathbb{R}$是当前节点的特征$Wh_i$与邻居节点特征$Wh_j$的函数:
$$\alpha_{ij}=\frac{\exp(\text{LeakyReLU}(a^T[Wh_i\Vert Wh_j]))}{\sum_{k\in\mathcal{N}_i}\exp(\text{LeakyReLU}(a^T[Wh_i\Vert Wh_j]))}$$
其中$a\in\mathbb{R}^{2F’}$是单层全连接网络的参数。
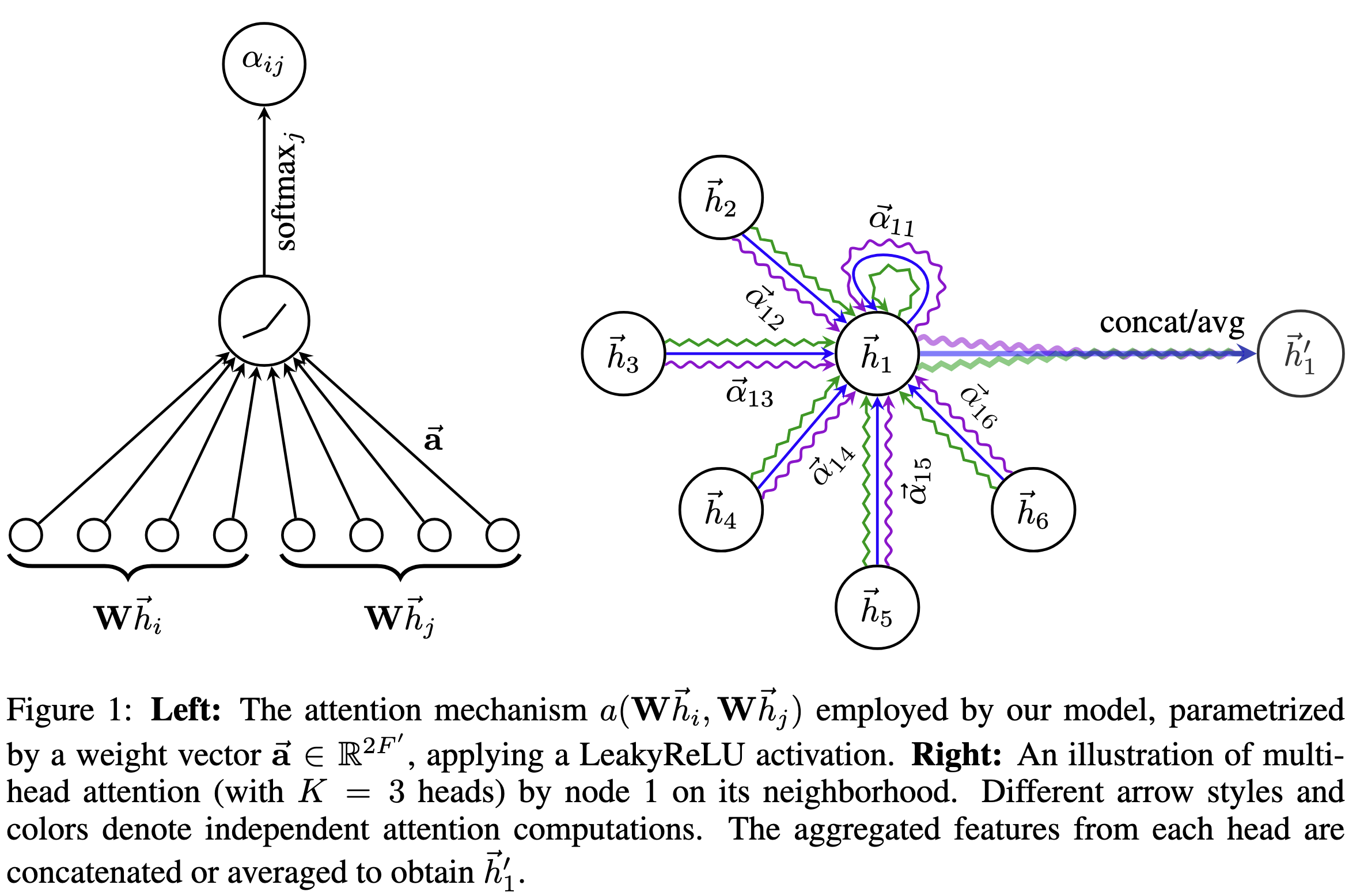
多头注意力机制可以使训练更稳定,输出是对所有输出头进行平均:
$$h_i’=\sigma\left(\frac{1}{K}\sum_{k=1}^K\sum_{j\in\mathcal{N}_i}\alpha^k_{ij}W^kh_j\right)\in\mathbb{R}^{2F’}$$
GAT中用于计算attention系数的$a\in\mathbb{R}^{2F’}$对所有边共享。这带来的一个好处是GAT可以直接应用于inductive归约的设定,即测试时的图结构在训练时不可见。
GIN: How Powerful are Graph Neural Networks?
( Citation: Xu, Hu & al., 2019 Xu, K., Hu, W., Leskovec, J. & Jegelka, S. (2019). How Powerful are Graph Neural Networks?. https://doi.org/10.48550/arXiv.1810.00826 ) 提出分析GNN表达能力的通用理论框架。作者发现现有GNN经常欠拟合训练数据,因此研究GNN的表达能力并设计理论上表达能力最强的GNN。
图同构问题和1-WL test
维基百科的问题定义:给定两个图$G,H$, 我们称$G$和$H$同构,如果存在一个双射$f:V(G)\mapsto V(H)$, 使得边$\langle u,v\rangle\in E(G)$当且仅当边$\langle f(u),f(v)\rangle\in E(H)$。
下面的例子中两个图看起来很不一样,但其实是同构的。
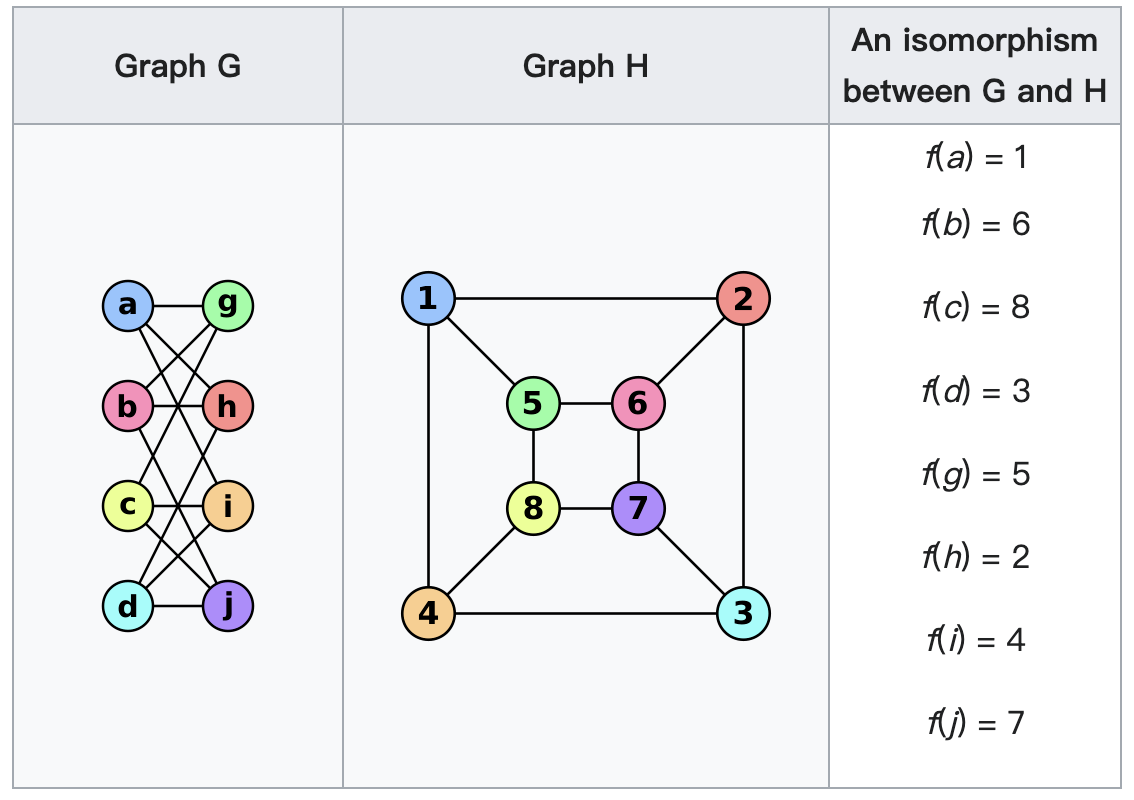
是否存在多项式时间的算法能精确解决图同构问题是未知的。1-dimensional Weisfeiler-Leman (1-WL) test是用于图同构问题的启发式算法。1-WL test可以分辨大多数不同构的图结构,但存在一些极端的不同构的例子1-WL test无法分辨。如果1-WL test输出两个图结构不同构,那么它们一定是不同构的,但反过来不一定成立。1-WL test的算法过程与GNN的消息传递机制类似,因此常用于分析GNN的表达能力 ( Citation: Huang & Villar, 2021 Huang, N. & Villar, S. (2021). A Short Tutorial on The Weisfeiler-Lehman Test And Its Variants. https://doi.org/10.1109/ICASSP39728.2021.9413523 ) 。
1-WL算法采用一个图作为输入,输出排序的节点标签。为了执行1-WL test比较两个图是否同构,分别对两个图执行1-WL算法,比较输出是否相同。
1-WL算法依赖一个单射函数作为哈希hash函数,即对于不同的输入,hash函数的输出必须是不同的。Hash函数用于给节点打标签。1-WL初始化每个节点具有相同的id,所以初始时每个节点具有相同的hash标签。接着,在每一轮,对于每个节点,将当前节点的标签和1阶邻居的标签拼接起来,排序,输入hash函数产生当前节点新的标签。如果发现更新后的节点标签分布(即标签排序后每个标签对应节点的个数)相较于更新前没有变化,那么算法终止。1-WL算法最终输出标签及对应的节点个数。算法的Python实现见链接。
GNN表达能力的分析框架
通过readout读出函数,GNN将输入的图结构映射到图表征向量。理想情况下,对于不同构的两个图结构,GNN应该将它们映射到不同的表征向量;反之对于同构的图结构应映射到相同的表征向量。这意味着希望GNN解决图同构问题。
首先,引理2证明了对于不同构的两个图$G_1,G_2$, 如果GNN能将它们映射到不同的表征向量,那么1-WL test同样能判别它们不同构。这意味着GNN至多具有1-WL test分辨不同构图结构的能力。
大多数消息传递GNN可以概括为如下形式:
$$\begin{aligned}a_v^{(k)}&=\text{AGGREGATE}\left(\left\{h_u^{(k-1)}:u\in\mathcal{N}(v)\right\}\right) \\ h_v^{(k)}&=\text{COMBINE}(h_v^{(k-1)},a_v^{(k)})\end{aligned}$$
其中$a_v^{(k)}$通过$\text{AGGREGATE}$聚合上一轮邻居的特征,$h_v^{(k)}$通过$\text{COMBINE}$聚合上一轮目标节点的特征与聚合后的邻居的特征。
定理3希望找到一种强大的GNN推导引理2的反定理。定理3证明了对于1-WL test能够分辨的不同构图结构$G_1,G_2$,在GNN堆叠层数够多时,当$\text{AGGREGATE}$,$\text{COMBINE}$和readout函数满足下列条件时,GNN能将$G_1,G_2$映射到不同的表征向量:
- $\text{AGGREGATE}$,$\text{COMBINE}$都是单射
- readout函数是单射
通过定理3定义的GNN具有与1-WL test相同的判别不同构图结构的能力。
GNN相比1-WL test的好处是可以通过输出的表征向量计算相似性,而1-WL test只能用于分辨不同构的图结构,无法计算相似性。
GIN
根据定理3,需要设计$\text{AGGREGATE}$,$\text{COMBINE}$满足单射函数。引理5证明了存在一个函数$f$使得$\text{AGGREGATE}=\sum_{x\in X}f(x)$是单射函数; 推论6证明了存在函数$f,\phi$和常数$\epsilon$,使得$\text{COMBINE}=\phi((1+\epsilon)\cdot f(c)+\sum_{x\in X}f(x))$是单射函数。
由于MLP可以拟合任意函数 ( Citation: Hornik, Stinchcombe & al., 1989 Hornik, K., Stinchcombe, M. & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2(5). 359–366. https://doi.org/10.1016/0893-6080(89)90020-8 ) ,以及上述$f,\phi$的存在性,作者定义GIN层的计算公式为
$$h_v^{(k)}=\text{MLP}^{(k)}\left((1+\epsilon^{(k)})\cdot h_v^{(k-1)}+\sum_{u\in\mathcal{N}(v)}h_u^{(k-1)}\right)$$
如果初始节点特征是独热one-hot向量,那么求和前不需要MLP,因为对独热向量求和本身就是单射。(否则需要MLP?)
readout函数也需要是单射. GIN的readout函数定义为
$$h_G=\text{CONCAT}\left(\text{READOUT}\left(\left\{h_v^{(k)}|v\in G\right\}\right)|k=0,1,…,K\right)$$
其中$K$表示GIN的层数。
GCN和GraphSAGE表达能力不如GIN的原因
许多GNN使用1层感知机($\sigma\circ W$)而不是MLP(多层感知机)。引理7证明了存在一类输入$X$使得任何1层感知机在$X$上都不是单射。
GCN使用$\text{MEAN}$作为$\text{AGGREGATE}$,GraphSAGE使用$\text{MAX}$,它们都不如GIN使用的$\text{SUM}$,如下图所示。$\text{SUM}$能够分辨一些$\text{MEAN}$和$\text{MAX}$无法分辨的结构和特征分布。
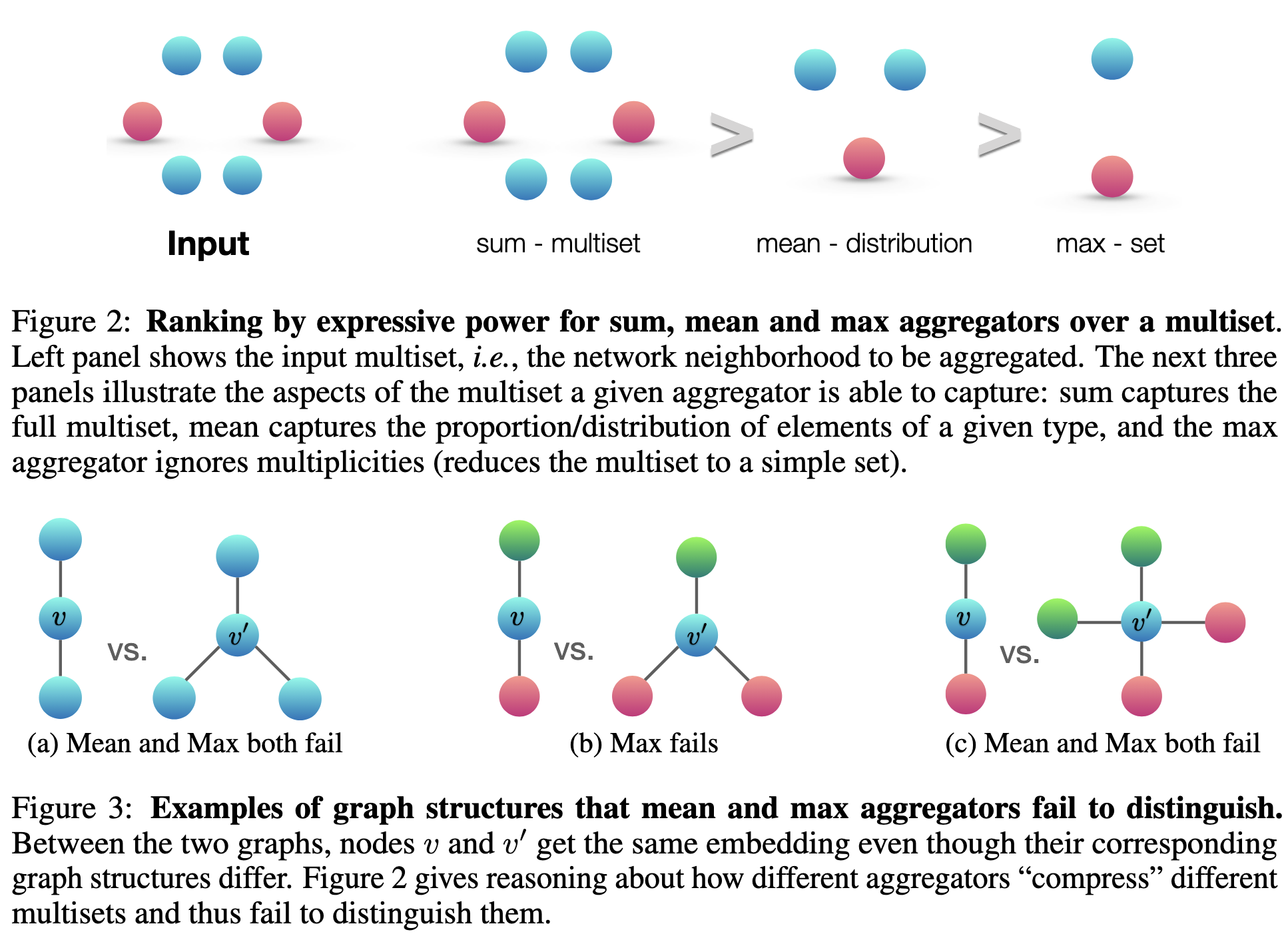
实验设置
本文使用图分别任务。数据集包含4个生物信息数据集和5个社交网络数据集。为了使模型完全从图结构中学习,作者删除原始的节点特征。在生物信息图上,节点带有类别特征;在社交网络上,节点没有特征。然而GNN包括GIN需要初始节点特征,因此对于社交网络,一部分数据集将所有节点赋予相同的特征,另一部分使用节点度的独热one-hot向量作为特征。
GIN的一个变体GIN-0将原本可训练的参数$\epsilon$固定为0.
实验结果
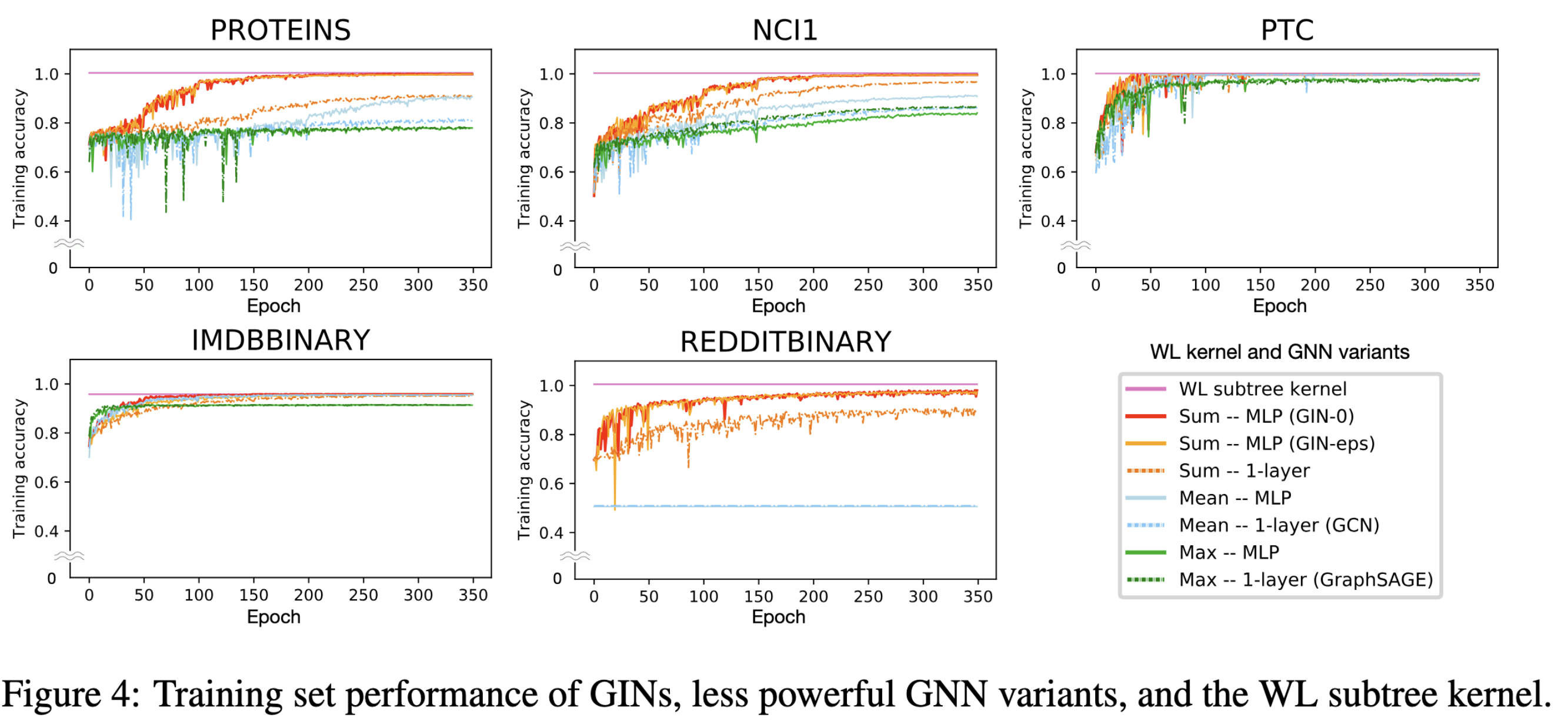
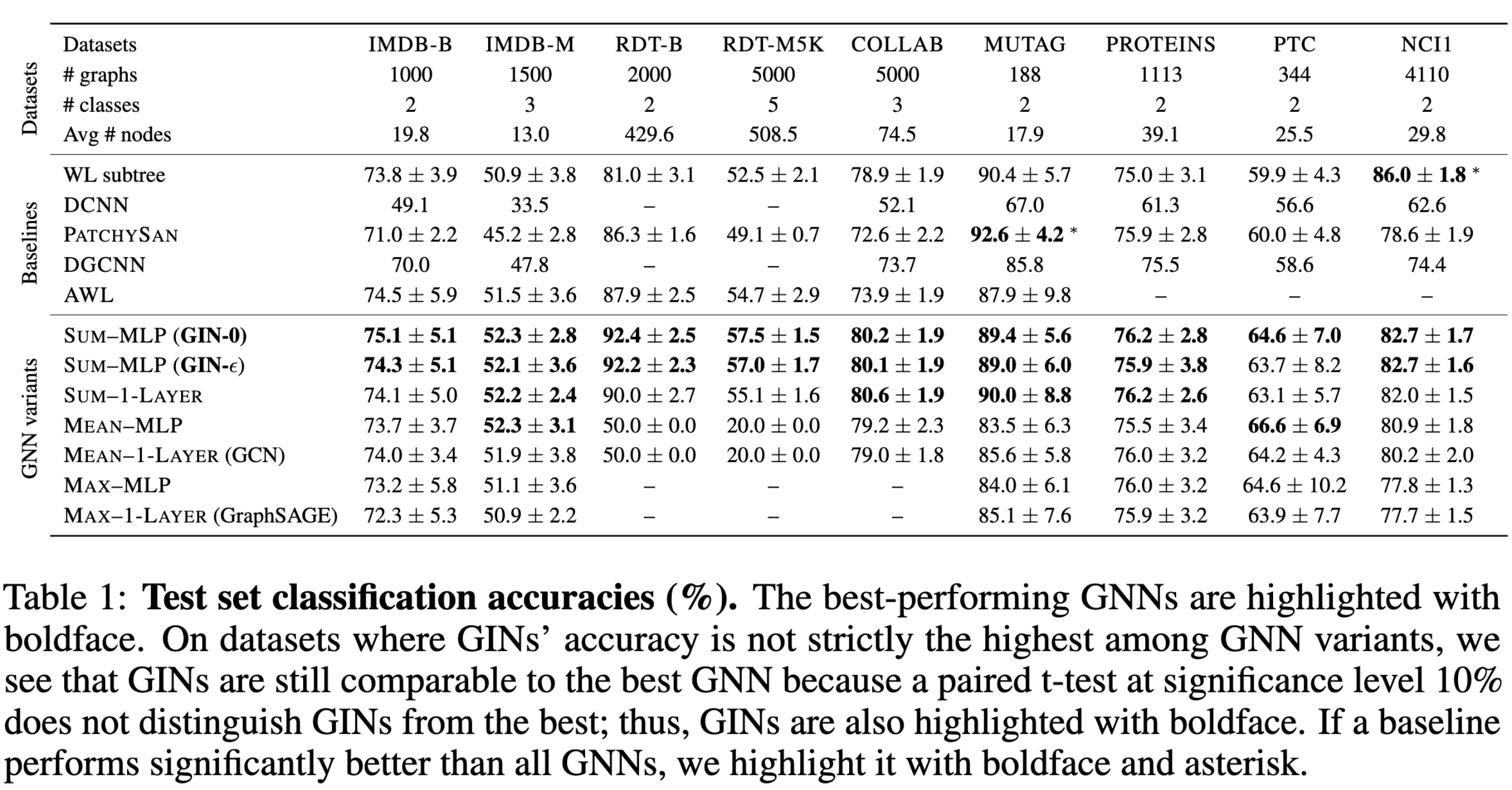
图4说明GIN能更好得拟合训练数据,因此表达能力更强。
表1说明GIN在测试集上具有较好的泛化能力,尽管这一点并没有理论证明。
Relational inductive biases, deep learning, and graph networks
( Citation: Battaglia, Hamrick & al., 2018 Battaglia, P., Hamrick, J., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V., Malinowski, M., Tacchetti, A., Raposo, D., Santoro, A., Faulkner, R., Gulcehre, C., Song, F., Ballard, A., Gilmer, J., Dahl, G., Vaswani, A., Allen, K., Nash, C., Langston, V., Dyer, C., Heess, N., Wierstra, D., Kohli, P., Botvinick, M., Vinyals, O., Li, Y. & Pascanu, R. (2018). Relational inductive biases, deep learning, and graph networks. https://doi.org/10.48550/arXiv.1806.01261 )Graph Neural Networks with Adaptive Readouts
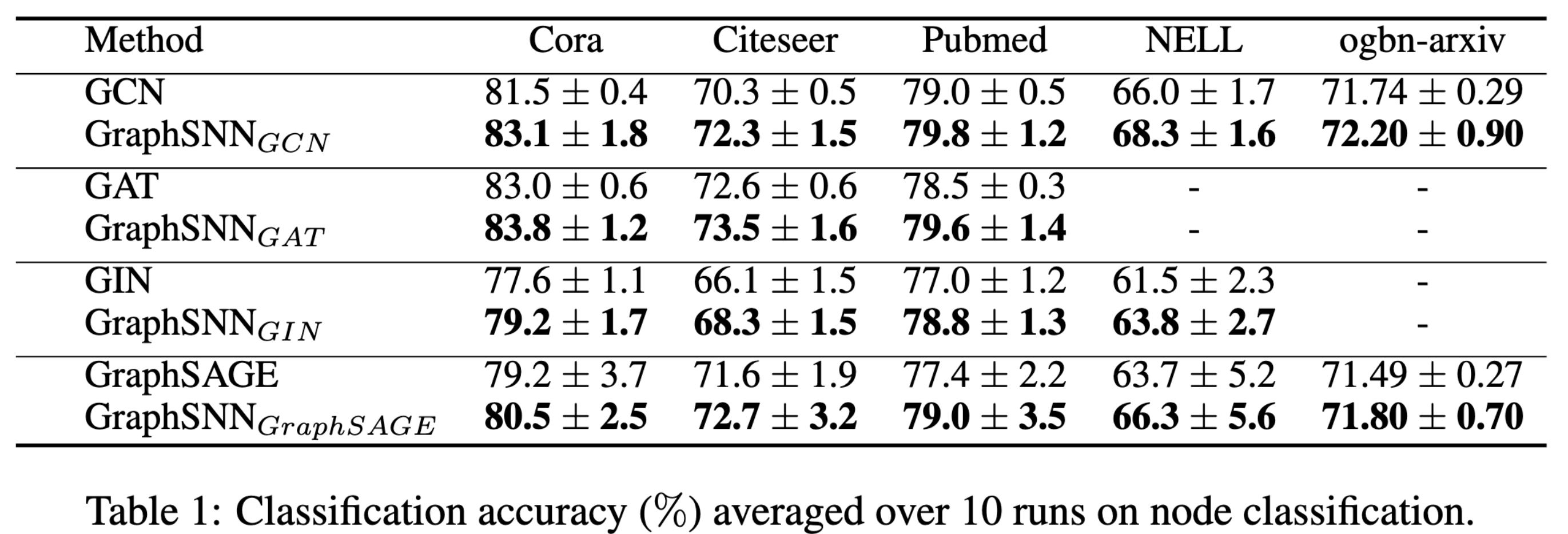
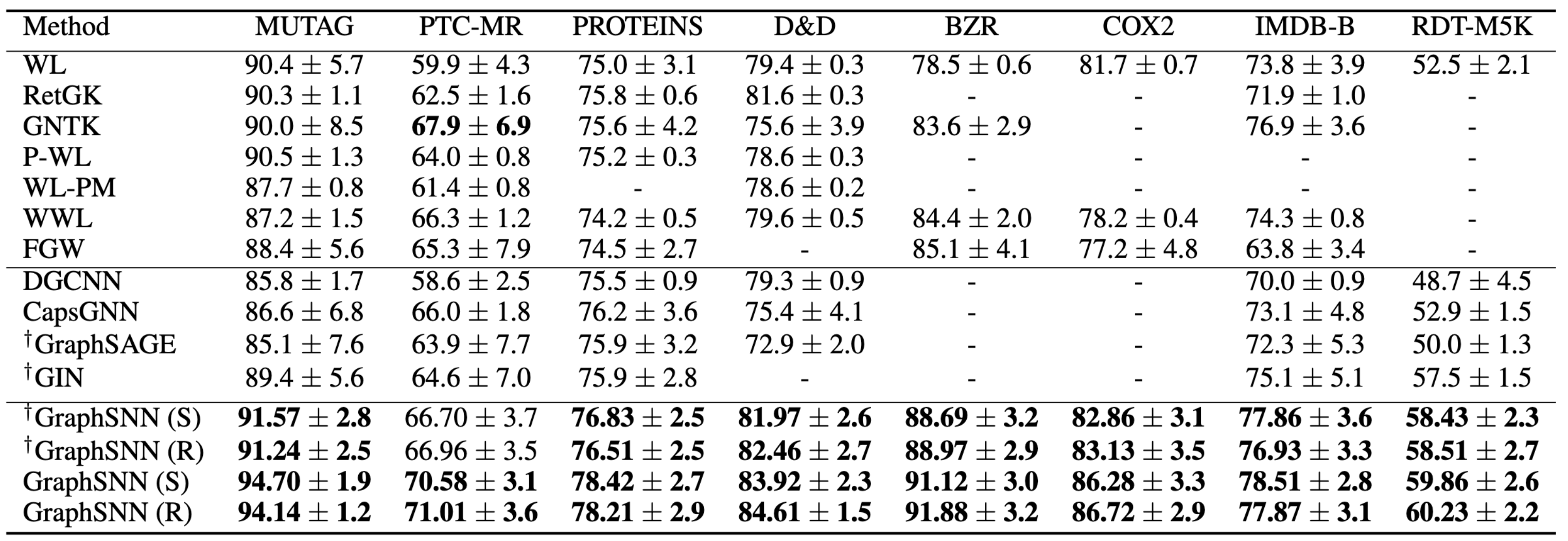
( Citation: Buterez, Janet & al., 2022 Buterez, D., Janet, J., Kiddle, S., Oglic, D. & Liò, P. (2022). Graph Neural Networks with Adaptive Readouts. https://doi.org/10.48550/arXiv.2211.04952 )GraphSNN: A New Perspective on “How Graph Neural Networks Go Beyond Weisfeiler-Lehman?”
( Citation: Wijesinghe & Wang, 2021 Wijesinghe, A. & Wang, Q. (2021). A New Perspective on “How Graph Neural Networks Go Beyond Weisfeiler-Lehman?”. Retrieved from https://openreview.net/forum?id=uxgg9o7bI_3 ) 提出了比GIN表达能力更强的GraphSNN,在节点分类和图分类任务上均比GIN有更好的表现,同时保留了较好的时间效率。对于图中的节点$i,j$,考虑它们的1阶邻居子图$S_i$,即$\tilde{N}(i)=\{v\in V|(i,v)\in E\}\cup \{i\}$导出的子图,作者定义了三种同构模式:
- 子图同构:$S_i$和$S_j$是同构的,且对应节点的特征向量相同;
- 重叠同构:对于$i$的任意1阶邻居$v’$,存在$j$的1阶邻居$u’$,使得$S_{iv’}=S_i\cap S_{v’}$与$S_{ju’}=S_j\cap S_{u’}$是同构的,且对应节点的特征向量相同;
- 子树同构:对于$i$的任意1阶邻居$v’$,存在$j$的1阶邻居$u’$,只满足$v’,u’$的特征向量相同。
子图同构的条件最强,最弱的是子树同构。如下图所示,左图中不满足子图同构,但满足重叠同构;右图不满足重叠同构,但满足子树同构。
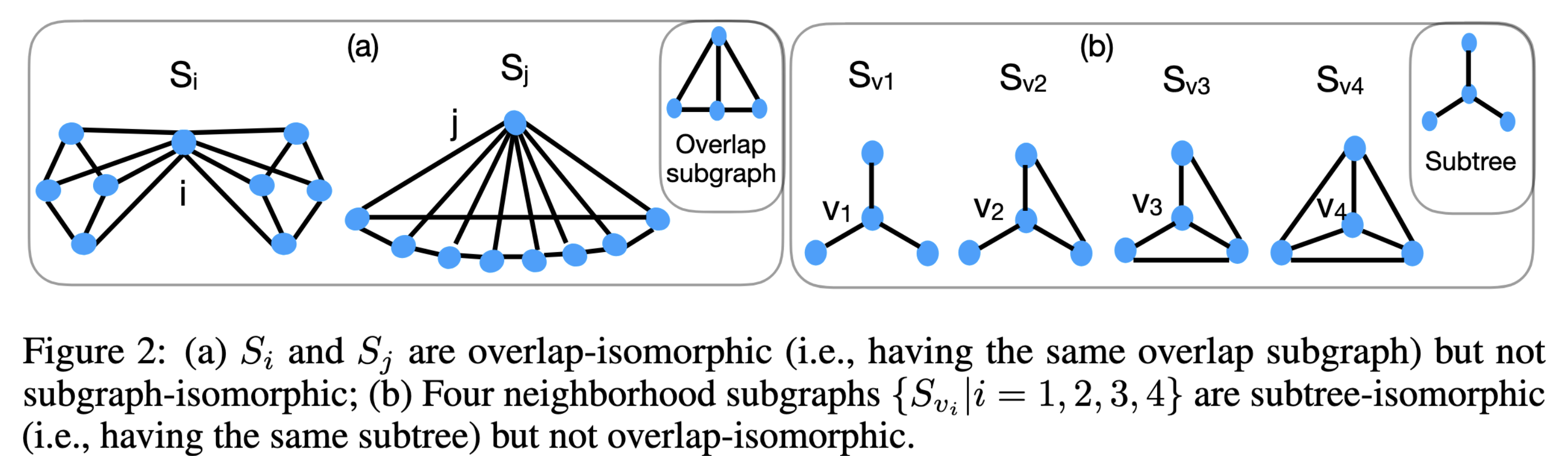
作者证明了GIN只能分辨子树不同构的节点。为了更好分辨两个节点的一阶邻居子图,作者希望定义一个数值参量衡量两个节点的邻居子图相似性:$\omega: \mathcal{S}\times \mathcal{S}^*\to \mathbb{R}$,其中$\mathcal{S}=\{S_v|v\in V\},\mathcal{S}^*=\{S_{vu}|(v,u)\in E\}$。$\omega$将目标节点的1阶邻居子图和目标节点与邻居节点的重叠子图映射到一个相似度数值,它衡量了目标节点和邻居节点的结构相似性。这样,GraphSNN可以从相似度高的邻居聚合更大比例的特征。
对于目标节点$v$和它的两个邻居$u,u’$,$\omega$需要满足3个性质:
- 局部紧密性:如果$S_{vu},S_{vu’}$都是完全图,但$S_{vu}$有更多的节点,那么$\omega(S_v,S_{vu})>\omega(S_v,S_{vu’})$;
- 局部稠密性:如果$S_{vu},S_{vu’}$有相同个数的节点,但$S_{vu}$有更多的边,那么$\omega(S_v,S_{vu})>\omega(S_v,S_{vu’})$;
- 同构不变性:如果$S_{vu},S_{vu’}$同构,那么$\omega(S_v,S_{vu})=\omega(S_v,S_{vu’})$。
下图展示了性质1和性质2的例子。
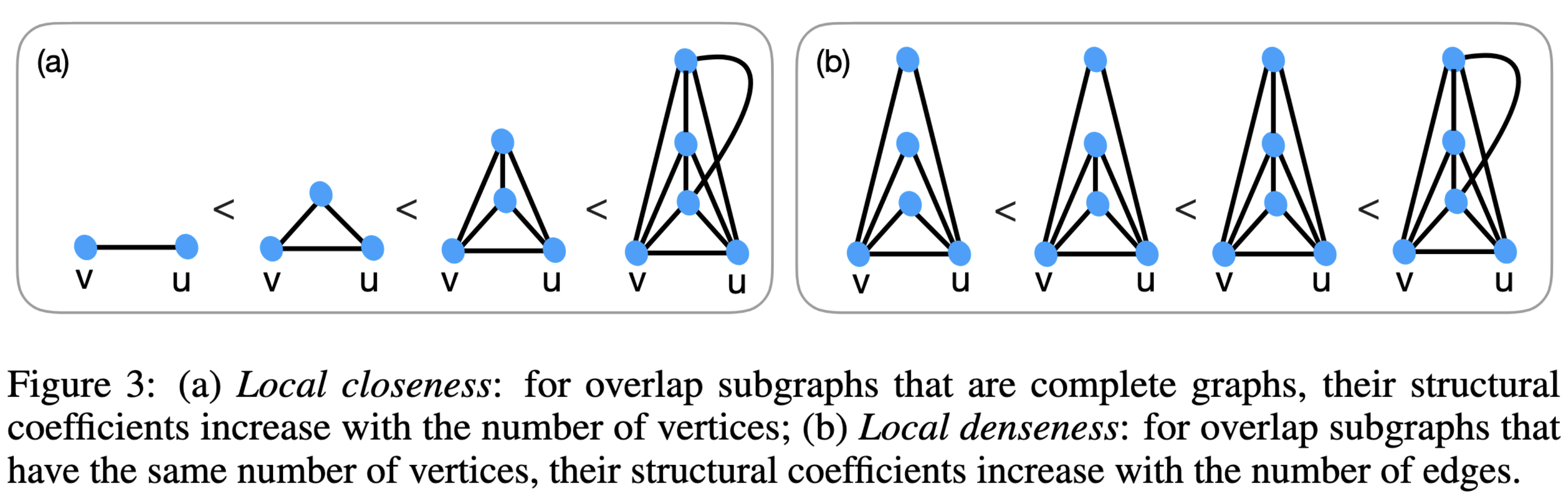
作者给出了一个$\omega$的例子:
$$\omega(S_v,S_{vu})=\frac{|E_{vu}|}{|V_{vu}|\cdot |V_{vu}-1|}|V_{vu}|^{\lambda}$$
其中$V_{vu},E_{vu}$分别表示$S_{vu}$的顶点集和边集,$\lambda>0$是超参。GraphSNN基于$\omega$定义:
$$h_{v}^{t+1}=\text{MLP}\left(\gamma^{(t)}\left(\sum_{u\in\mathcal{N}(v)}\tilde{A}_{vu}+1\right)h_v^{(t)}+\sum_{u\in\mathcal{N}(v)}\left(\tilde{A}_{vu}+1\right)h_v^{(t)}\right)$$
其中$\tilde{A}_{vu}$对每个节点$v$的邻居节点相似度做了归一化,即
$$\tilde{A}_{vu}=\frac{\omega(S_v,S_{vu})}{\sum_{u’\in\mathcal{N}(v)}\omega(S_v,S_{vu’})}$$
作者证明了GraphSNN相比1-WL test具有更强的分辨非同构子图的能力,因此强于GIN。实验结果也显示GraphSNN在节点分类和图分类任务上都有更好的准确度,如下图所示。