DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
研究动机 – 数据混合比例
大模型的训练数据是多种来源混合的。例如,著名的The-pile数据集,包含了24%的网页数据、9%的维基百科数据和4%的Github数据等。 ( Citation: Xie, Pham & al., 2023 Xie, S., Pham, H., Dong, X., Du, N., Liu, H., Lu, Y., Liang, P., Le, Q., Ma, T. & Yu, A. (2023). DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining. https://doi.org/10.48550/arXiv.2305.10429 ) 研究了多来源数据的混合比例问题。对于The-pile数据集,DoReMi首先训练一个280M参数量的与下游任务是无关的模型,用于生成每种数据的比例;接着,按这种比例重新采样数据,并训练一个目标大规模模型(8B)。结果表明大模型在每个数据源上都获得性能提升,即使在做了下采样的数据源上。
现有得到数据比例的方法有启发式方法(The-pile)和基于下游任务的方法(PaLM、GLaM)。然而,启发式方法可能是次优的;基于下游任务的方法通常需要在多个任务和多种数据混合比例上训练上千个模型,并且在特定任务上有过拟合的风险。
问题设置
假设存在$k$个数据域(domain,如维基百科、Github等)。每个域的数据记为$D_i$。每个域$i$的权重$\alpha_i$定义了数据采样的分布$P_{\alpha}$,即
$$P_{\alpha}=\sum_{i=1}^k\alpha_i\cdot\text{Unif}(D_i)=\sum_{i=1}^k\alpha_i\cdot\frac{1}{|D_i|}\sum_{x\in D}\delta_{x}$$
其中,$\delta_x(x’)=1$当且仅当$x’=x$,否则为$0$。例如,对于任意一个属于域$i$的样本$x’$,采样到它的概率为
$$P_{\alpha}(x’)=\sum_{i’=1}^k\alpha_{i’}\frac{1}{D_i}=\frac{\alpha_i}{|D_i|}$$
这样,数据采样的过程可看作独立的两步:第一步以$\alpha$分布采样一个域,第二步以均匀分布从该域中采样数据点。 本文提出的DoReMi方法致力于找到最优的$\bar{\alpha}$,并利用分布$P_{\bar{\alpha}}$采样的数据训练最终的大模型。
解决方案 – DoReMi
第一步,训练一个小规模参照模型(reference model)。其中,对照的训练数据域权重$\alpha_{\text{ref}}$可设置为均匀分布;
第二步,准备一个小规模代理模型(proxy model),初始化模型权重为$\theta_0$。初始化数据源权重$\alpha_0$为均匀分布。训练$T$代,每代得到一个数据源权重$\alpha_t$,最终返回$\bar{\alpha}=\frac{1}{T}\sum_t\alpha_t$。
在每个训练代$t\in T$,首先均匀采样一批数据$B=\{x_1,\cdots,x_b\}$作为训练数据。接着,先计算当前代理模型与对照模型的loss差异$\lambda_t$:
$$\lambda_t[i]\gets \frac{1}{\sum_{x\in B\cap D_i}|x|}\sum_{x\in B\cap D_i}\sum_{j=1}^{|x|}\max\{l_{\theta_{t-1},j}(x)-l_{\text{ref},j}(x),0\}$$
其中$l_{\cdot,j}(x)$表示$x$的第$j$个token的loss值。可以发现,右式中,乘法第一项对所有token取平均;第二项对所有token遍历;第三项逐token计算代理模型与参照模型的差异,并用$\max$忽略代理模型好的情况。那么,$\lambda_t[i]$表示了当前训练代在域$i$上代理模型比参照模型差了多少。 接着,由$\lambda_t$更新$\alpha_t$:
$$ \begin{align} \alpha_t’ &\gets \alpha_{t-1}\exp(\eta \lambda_t) \\ \alpha_t &\gets (1-c)\frac{\alpha_t’}{\sum_{i=1}^k\alpha_t’[i]}+cu \end{align} $$
其中$\eta=1,c=10^{-3}$为超参数。可以看到,差异$\lambda_t[i]$越大,域权重$\alpha_t[i]$的增幅越大。这表示在后续训练大模型时希望加入更多域$i$的数据。
最后,利用如下的$\min_\theta\max_{\alpha}L(\theta,\alpha)$更新代理模型的模型权重:
$$\min_\theta\max_{\alpha}L(\theta,\alpha)=\min_\theta\max_{\alpha}\sum_{i=1}^k\alpha_i\cdot\left[\frac{1}{\sum_{x\in D_i}|x|}\sum_{x\in D_i}l_{\theta}(x)-l_{\text{ref}}(x)\right]$$
其中$|x|$表示$x$包含的token个数,$l_{\theta}(x)=-\log p_{\theta}(x),l_{\text{ref}}(x)=-\log p_{\text{ref}}(x)$表示负对数似然损失函数。
需要注意的是,代理模型更新参数只更新$\theta$,$\alpha$在模型更新时是静态的。因此,在理解$L(\theta,\alpha)$时,$\max_{\alpha}$首先挑选出了使得当前代理模型最差的数据源分布$\alpha$,得到与参照模型差异最大的损失值;接着,$\min_\theta$更新$\theta$最小化这个最大的损失值。换句话说,代理模型是在优化最坏的情况。
$\sum_{i=1}^k\alpha_i\cdot\left[\frac{1}{\sum_{x\in D_i}|x|}\sum_{x\in D_i}l_{\theta}(x)-l_{\text{ref}}(x)\right]$是一个加权平均。要控制$\alpha$得到该加权平均的最大值,在$\sum_i\alpha_i=1$的条件下,$\max_{\alpha_i}\left(\sum_i\alpha_i\cdot C_i\right)=\max_i(C_i)$,这是因为
$$\max(C_i)-\sum_i\alpha_i\cdot C_i=\sum_i\left(\max(C_i)-C_i\right)\alpha_i\ge 0$$
其中$C_i$是常数,$i=1,2,\cdots,N$。 因此,$\min_\theta\max_{\alpha}L(\theta,\alpha)$先挑出了代理模型最差的数据域,并优化代理模型在这个域上的性能。
第三步,利用$\bar{\alpha}$重新采样数据集,并在其上训练大模型。
DoReMi框架可以迭代式地执行,即将前一次的$\bar{\alpha}$作为这次的参照模型的训练数据域分布$\alpha_{\text{ref}}$。
实验
本文采用两个数据集:The pile数据集和GLaM数据集,后者曾用于训练谷歌的PaLM模型。 模型架构使用纯解码器的Transformer模型。参照模型和代理模型默认都拥有280M的参数量。参照模型和代理模型始终拥有相同的参数量。
验证模型性能时有两种方式。第一种是使用留出验证集计算pplx;第二种是使用1-shot的下游生成任务,此时计算匹配准确度。
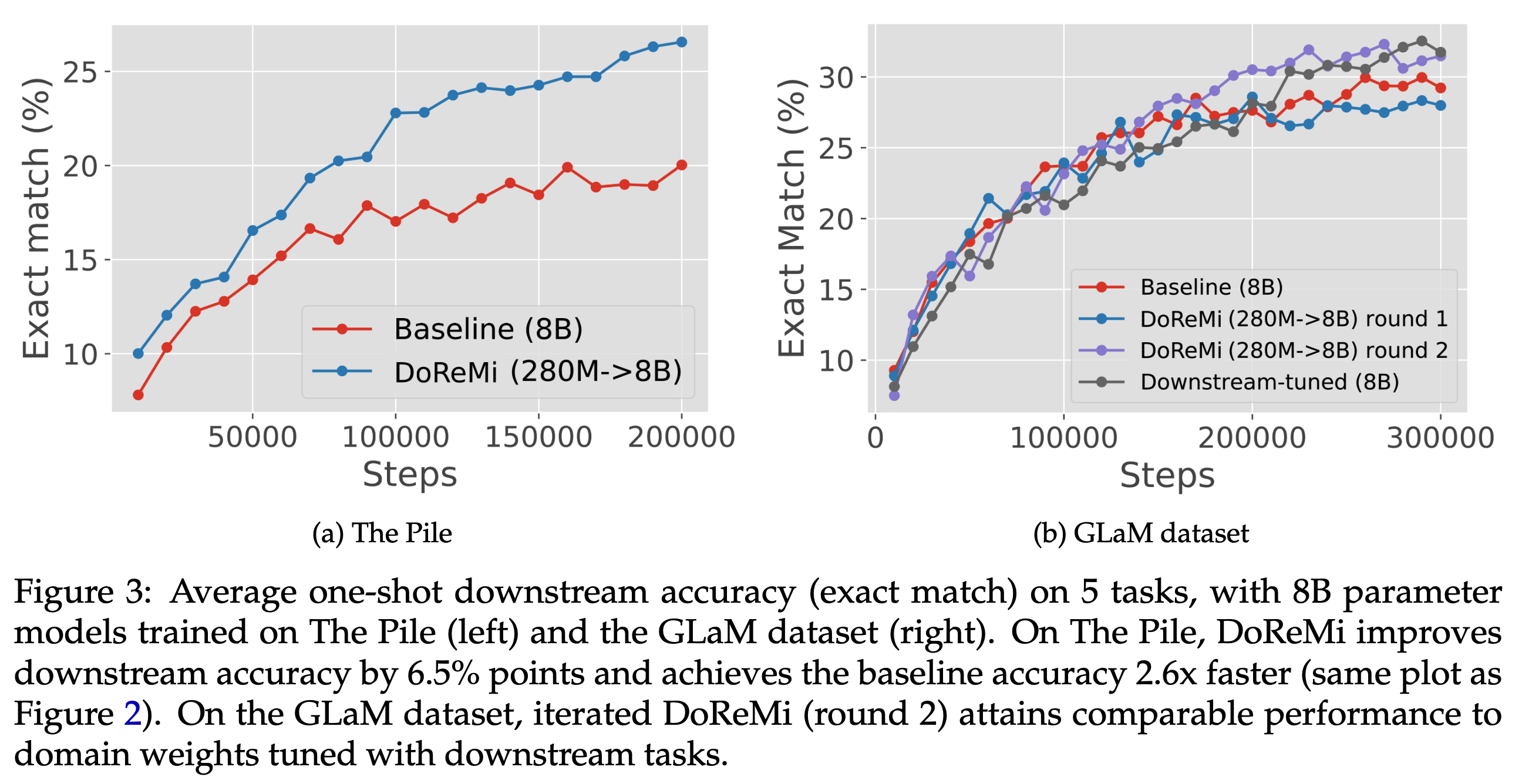
DoReMi在The pile数据集上明显优于使用The pile原始数据集训练的基线模型。在GLaM数据集上与使用下游任务调整数据权重的方法性能相当。
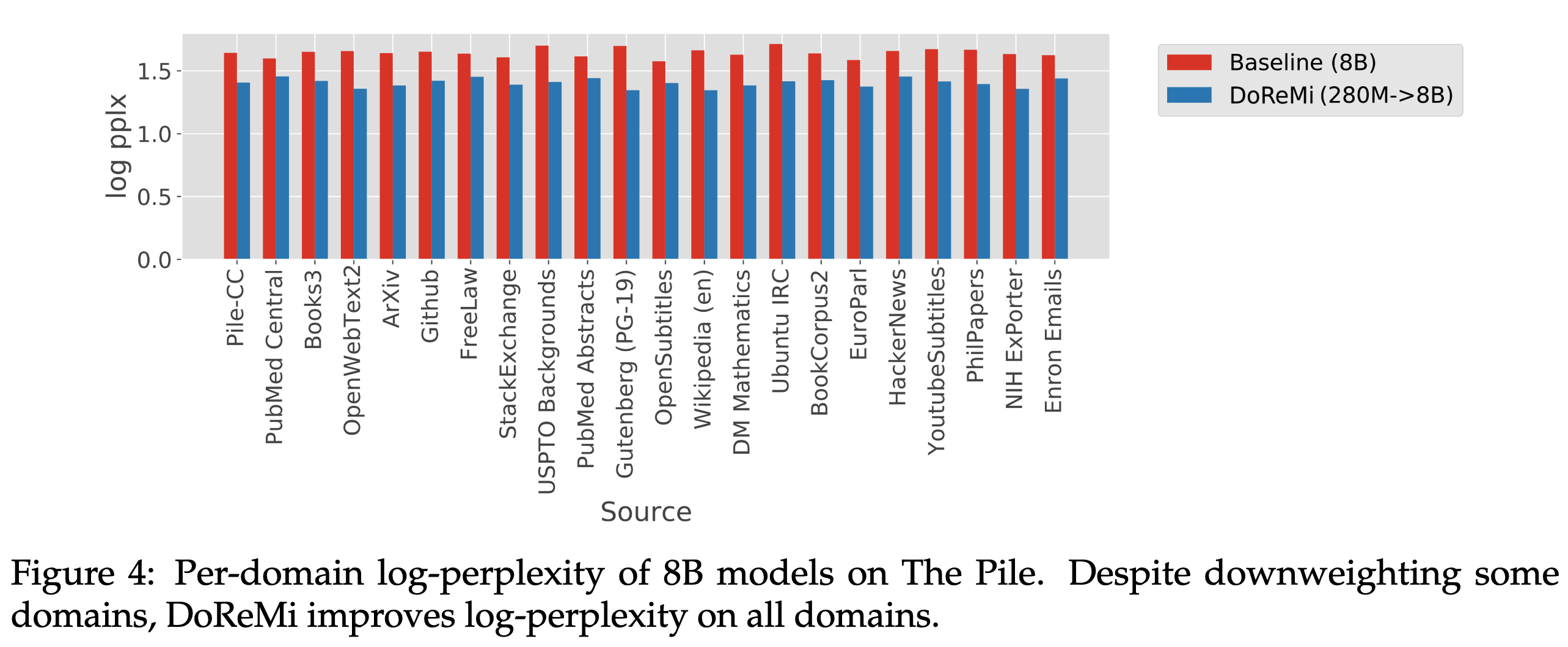
DoReMi在所有数据域上均获得性能提升,而不存在数据域之间的“trade off”。作者做出了解释。首先,具有高熵和低熵的数据域不需要过多的样本训练。低熵的数据很容易学习;高熵的数据的token趋于均匀分布,而初始化后的模型就能够在token后随机地输出下一个token。第二,中等熵的数据需要更多的样本进行训练。
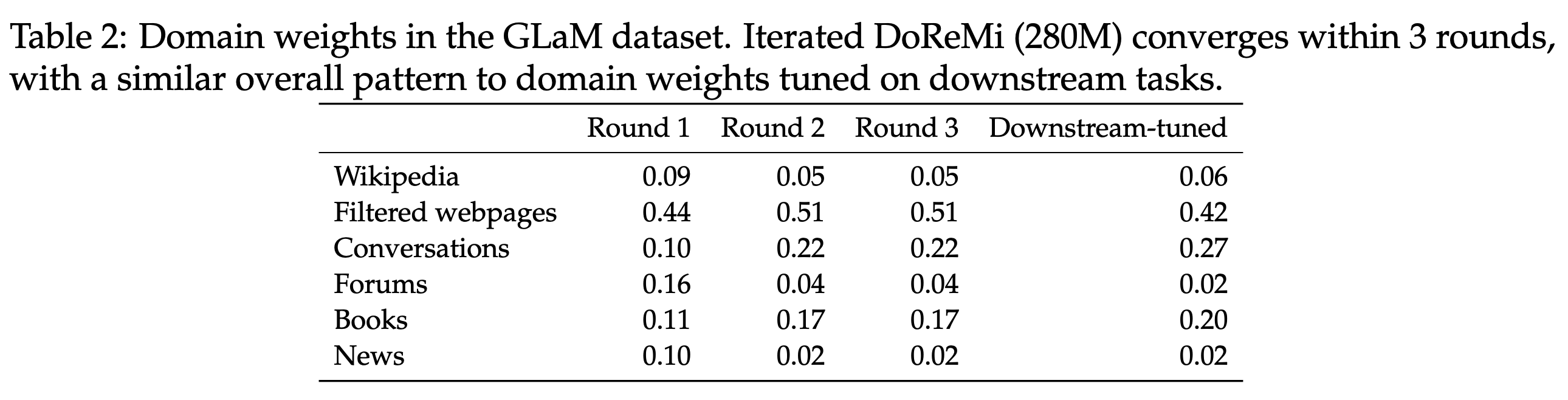
在GLaM数据集上,迭代的DoReMi取得与基于下游任务调整数据权重的方法相似的结果。作者发现该数据集变换数据源权重对结果的影响相对较少,可能是因为GLaM相比The pile的域划分($8<22$)更粗糙。
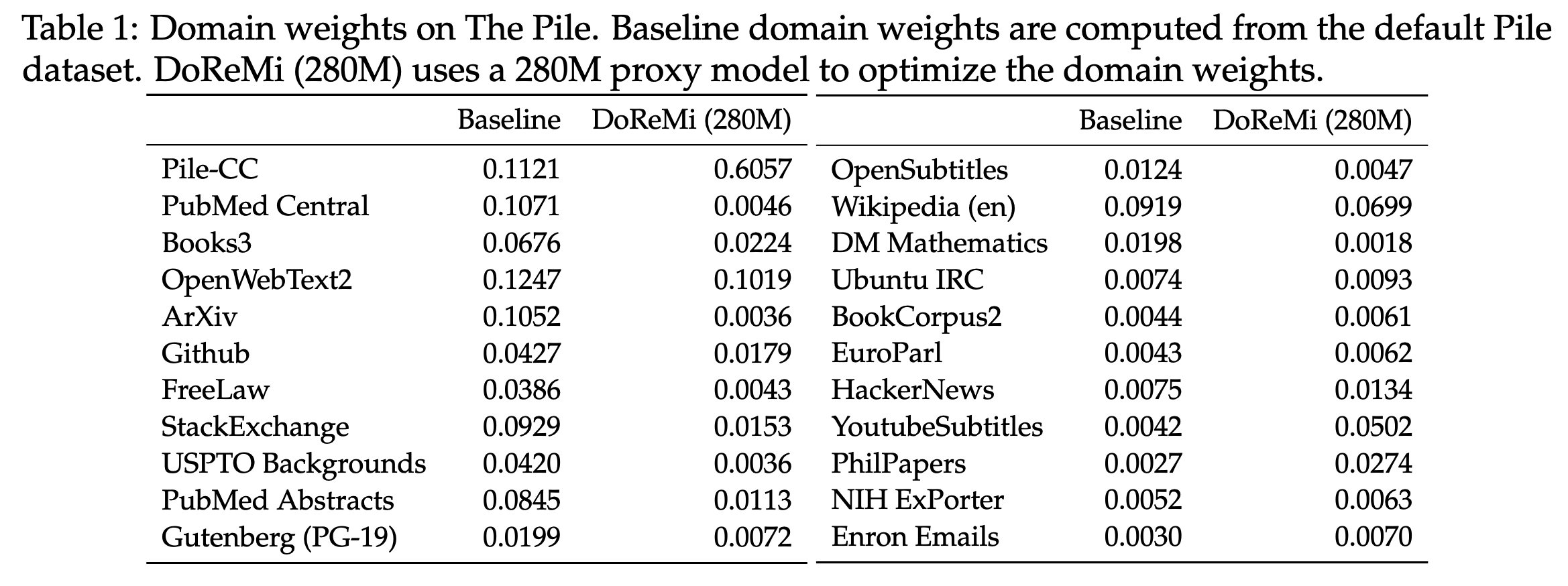
作者展示了DoReMi学习到的数据权重与原始权重的对比。注意到DoReMi在维基百科数据集上做了下采样,但仍然在该域的下游任务上取得性能提升。
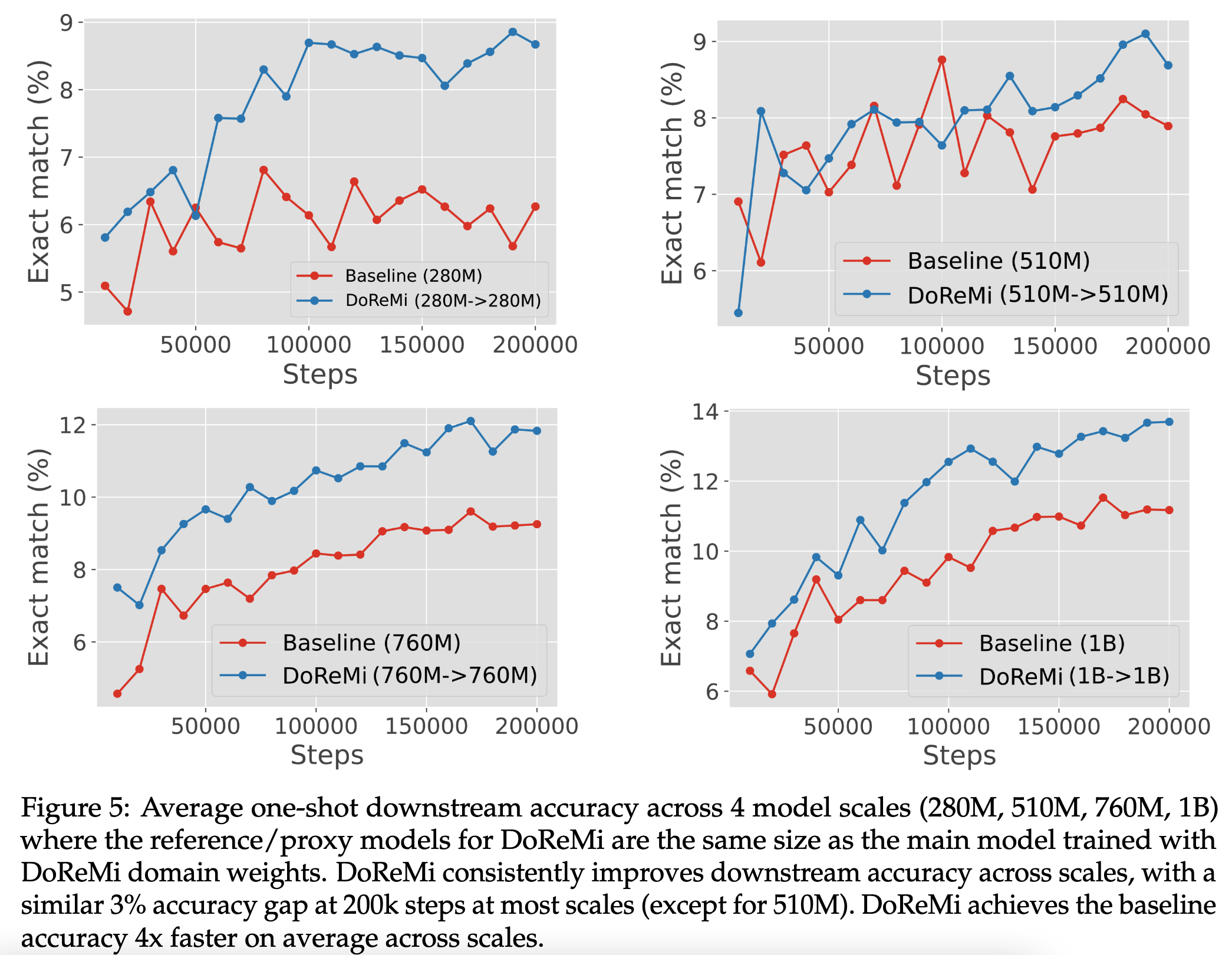
作者将参照模型、代理模型和最终的大模型的参数量统一,观察到在不同参数量规模时DoReMi均能获得性能提升。
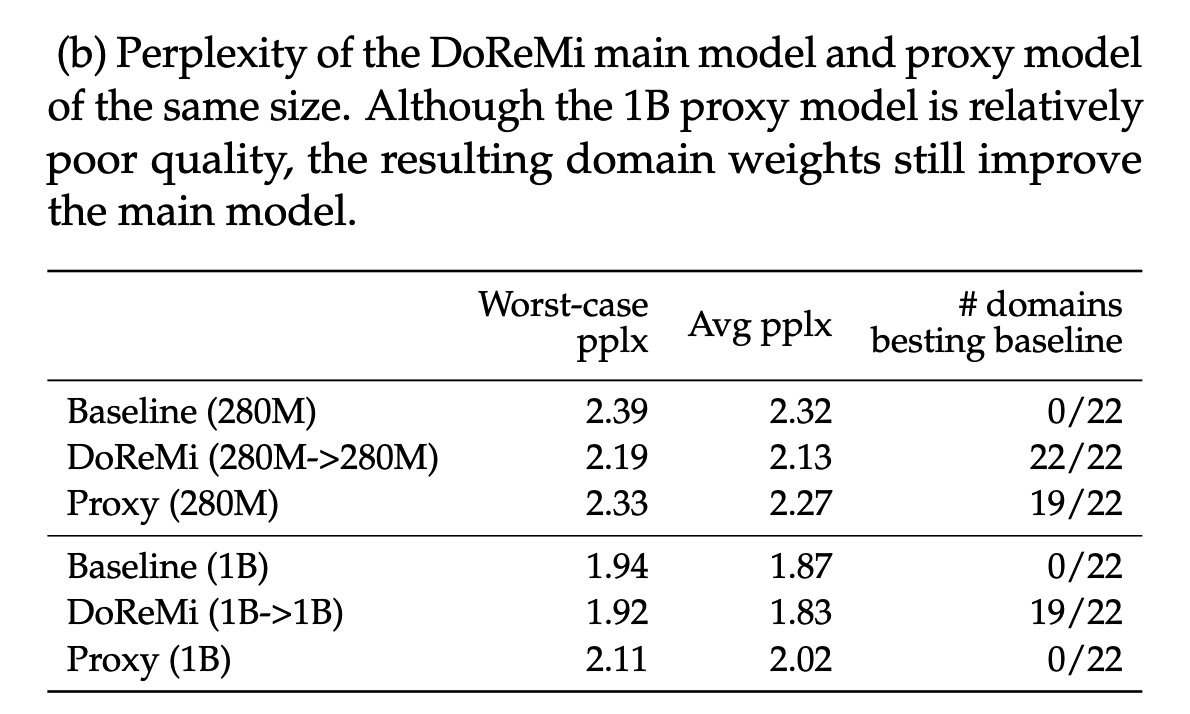
在参数量一致时,代理模型和最终的大模型哪个更好呢?作者发现,大模型的表现更好,尤其在参数量较大时。代理模型使用加权的损失函数训练,而大模型使用标准的损失函数在重新采样后的数据上训练。训练损失的不同导致了两个模型性能的差异。在参数量增大时差异扩大。作者最后假设使用重采样的代理模型可能能提升代理模型的性能,进而优化DoReMi?
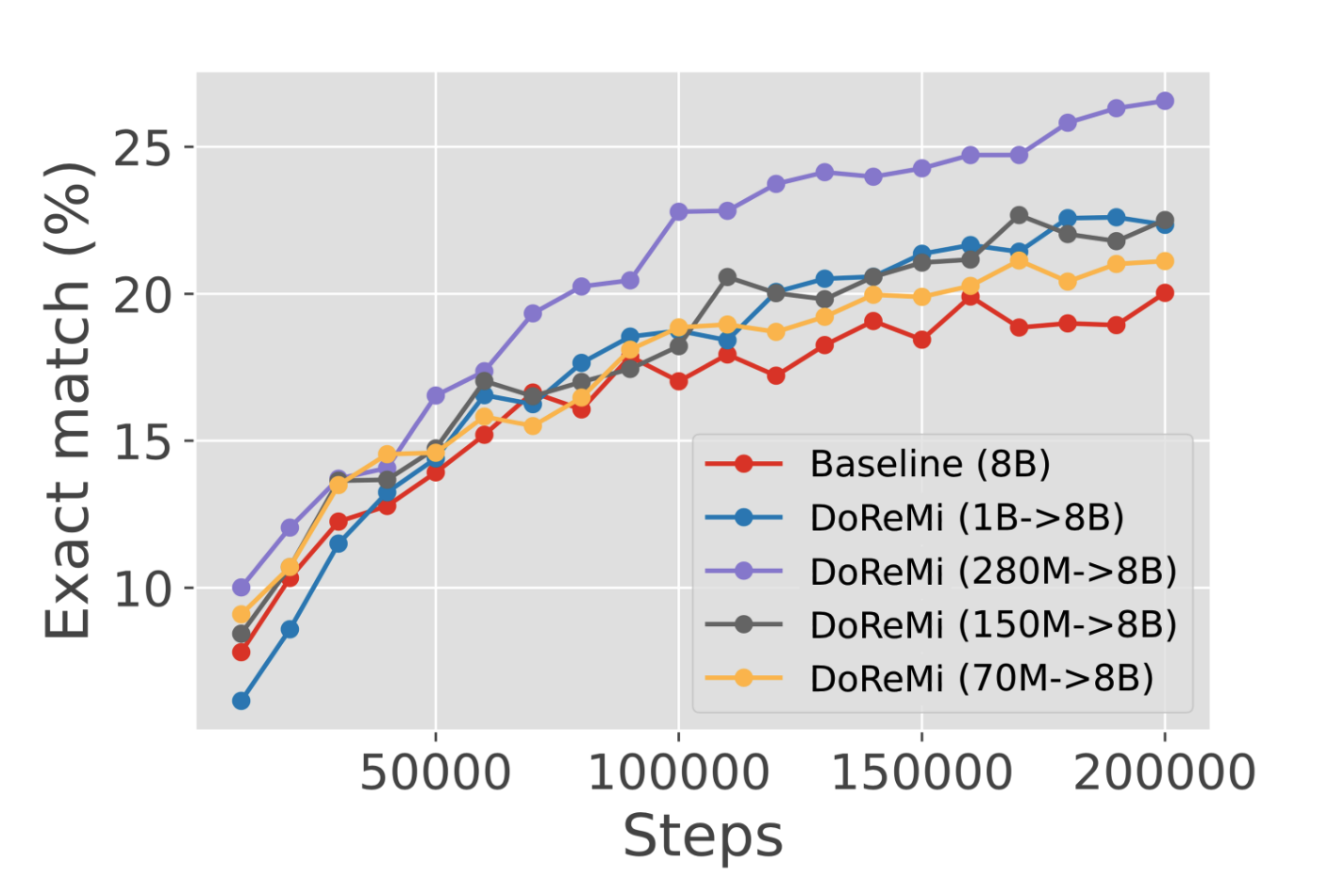
作者验证了不同大小的代理模型对大模型性能的影响。结果显示当前采用的280M代理模型的提升最大,同时其他规格的代理模型相对基线方法也有一定提升。
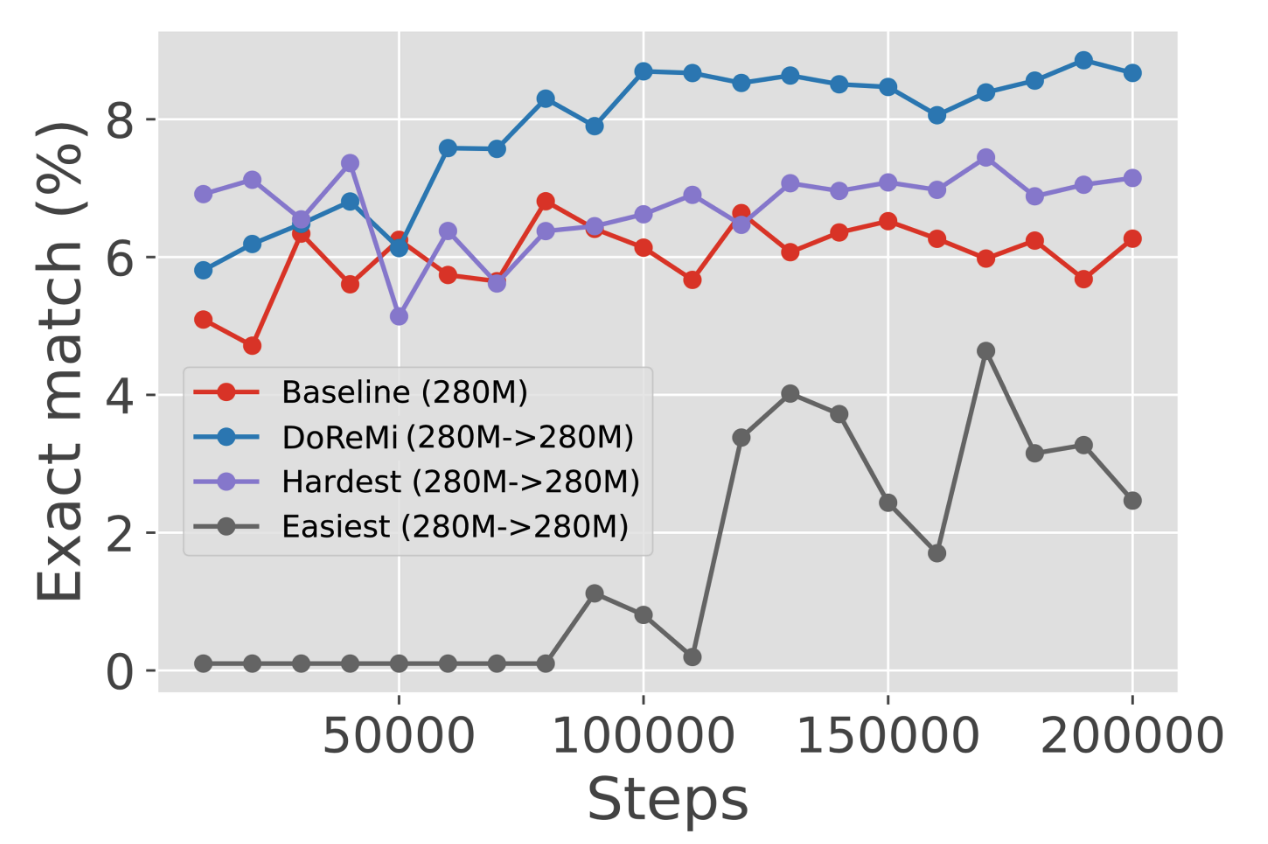
作者将代理模型的损失函数中的$l_{\theta}(x)-l_{\text{ref}}(x)$替换为$l_{\theta}(x)$,即"hardest",或替换为$-l_{\text{ref}}(x)$,即"easiest",发现均不如当前的设定。
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
( Citation: Wenzek, Lachaux & al., 2019 Wenzek, G., Lachaux, M., Conneau, A., Chaudhary, V., Guzmán, F., Joulin, A. & Grave, E. (2019). CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. https://doi.org/10.48550/arXiv.1911.00359 ) 提出并开源了语料清洗框架CCNet,能够对语料进行去重、语言识别和质量筛选。
相关工作 – 数据预处理
在词嵌入(word embedding)的背景下,已有针对数据预处理的研究,包括word2vec,GloVe,fastText等。CCNet采用与fastText相似的去重和语言识别步骤,并在后续添加了质量筛选步骤。 CCNet可以应用于广泛的语言数据集预处理任务,适用于多语言。
CommonCrawl
Common Crawl是一个网站,每个月都会发布随机爬取的网页快照,提供了大规模的语料数据。每个月之间的重复性很低。目前为止,完整的Common Crawl数据集已经包含8年的网页快照数据。爬取的网址没有限制,包括了多语言的网页,同时语料的质量也会参差不齐。因此,清洗Common Crawl的语料数据成为一大挑战。
每个网页快照包含3种格式的数据:原始数据WARC、UTF-8文本WET、元数据WAT。CCNet专注于对WET格式数据的清洗。
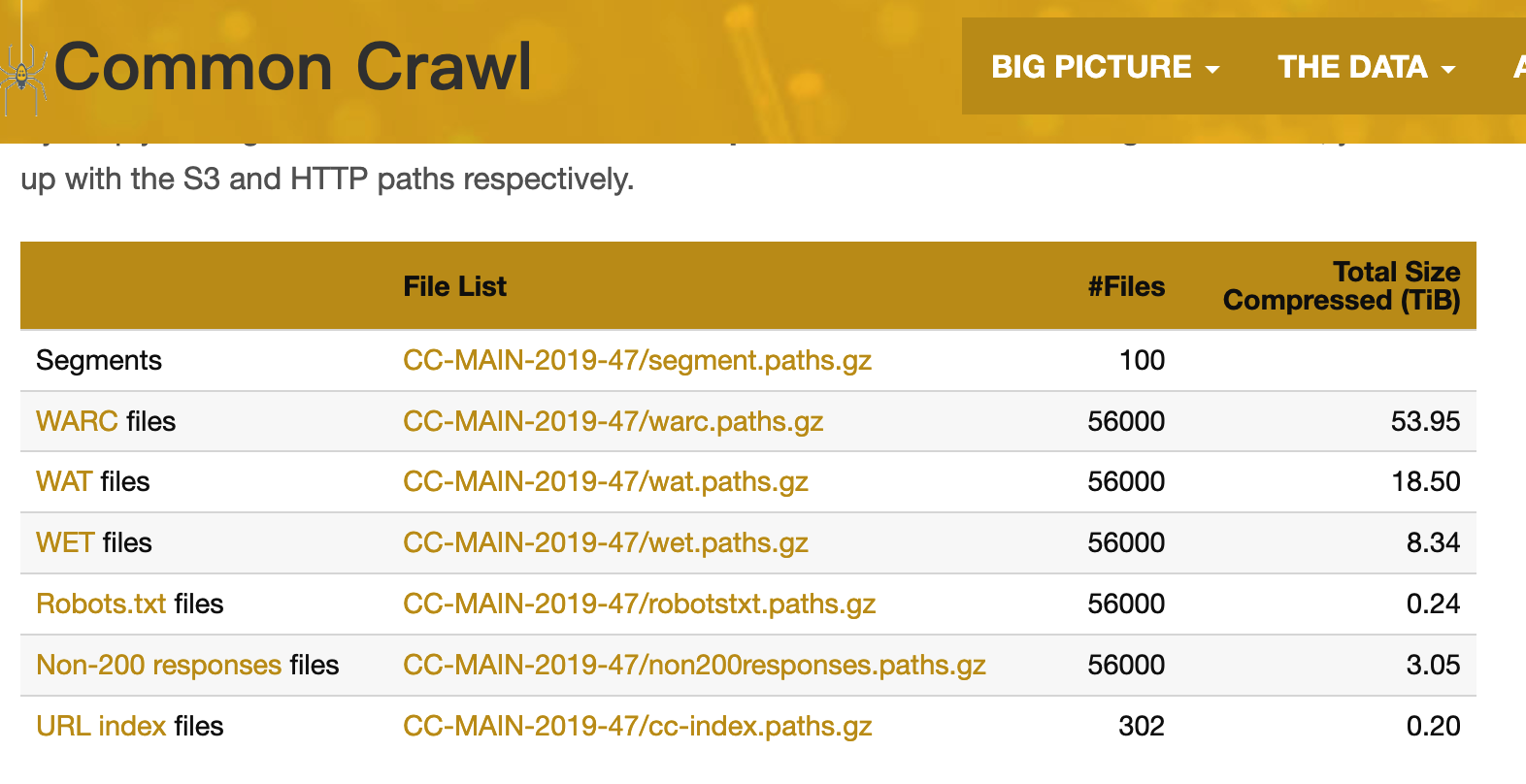
解决方案 – CCNet
每个月的数据在未压缩情况下有20~30TB的纯文本,对应于大约30亿个网页。例如,2019年2月有24TB的数据。CCNet采用分块的处理方法,将每个月的数据划分成1600块,每一块包含约5GB的WET数据。
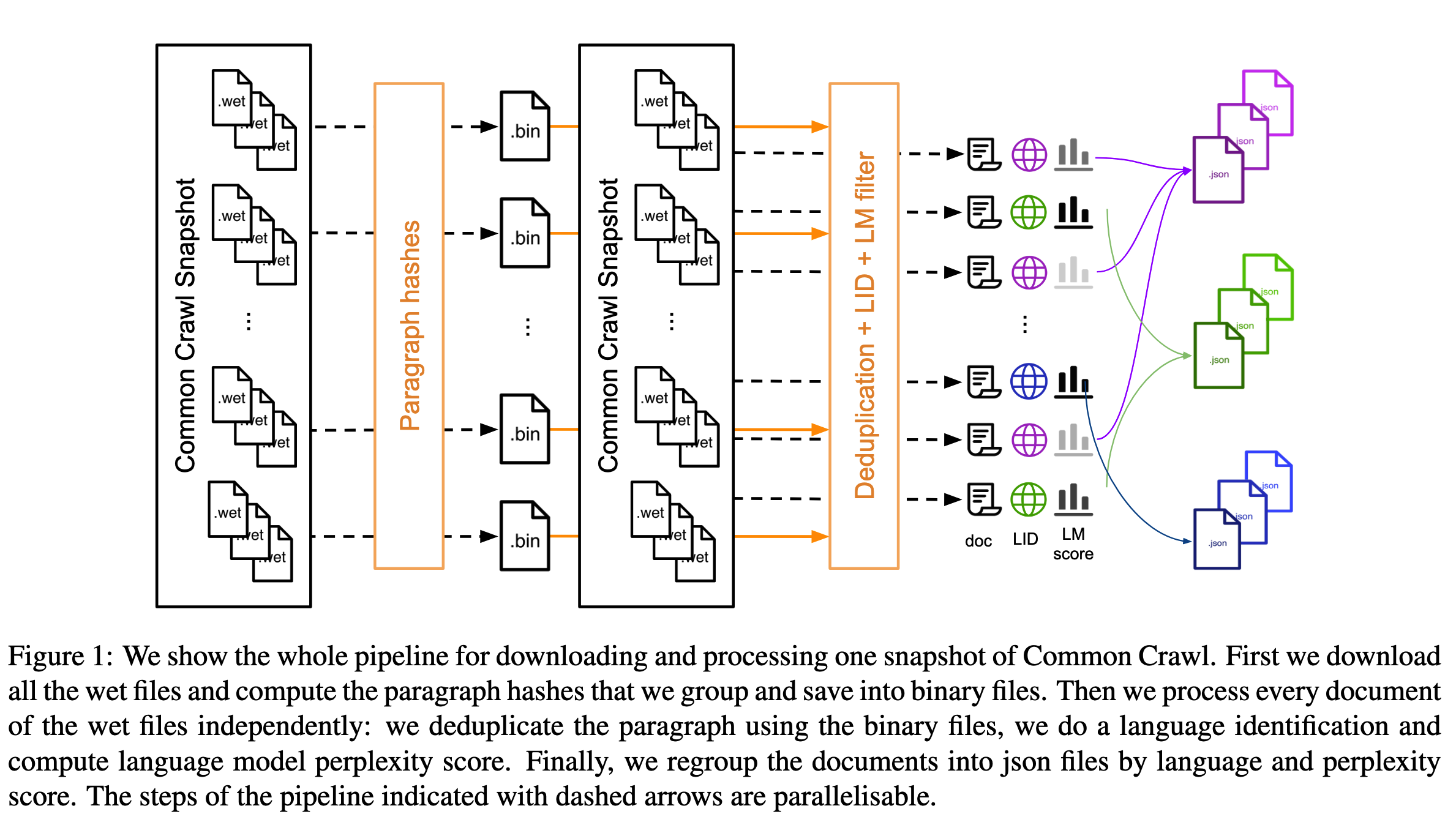
去重
在去重前,CCNet对文本进行规范化,包括统一转换为小写,用占位符替换数字,删除所有Unicode标点符号和重音符号等。 接着,在每个5GB块内,计算每个段落的SHA-1 HASH值,并且只取前64位作为该段落的标识符。利用标识符对段落进行去重。 去重操作仅在一定数量的块进行,不同块之间相互独立,因此可以并行多个块的去重操作。 除了删除相同的网页之外,去重还能够删除许多样板语料,如导航菜单、cookie警告和联系方式等。特别地,去重能够删除其他语言中大量重复的英文数据,这有利于提升后续预言识别的准确度。
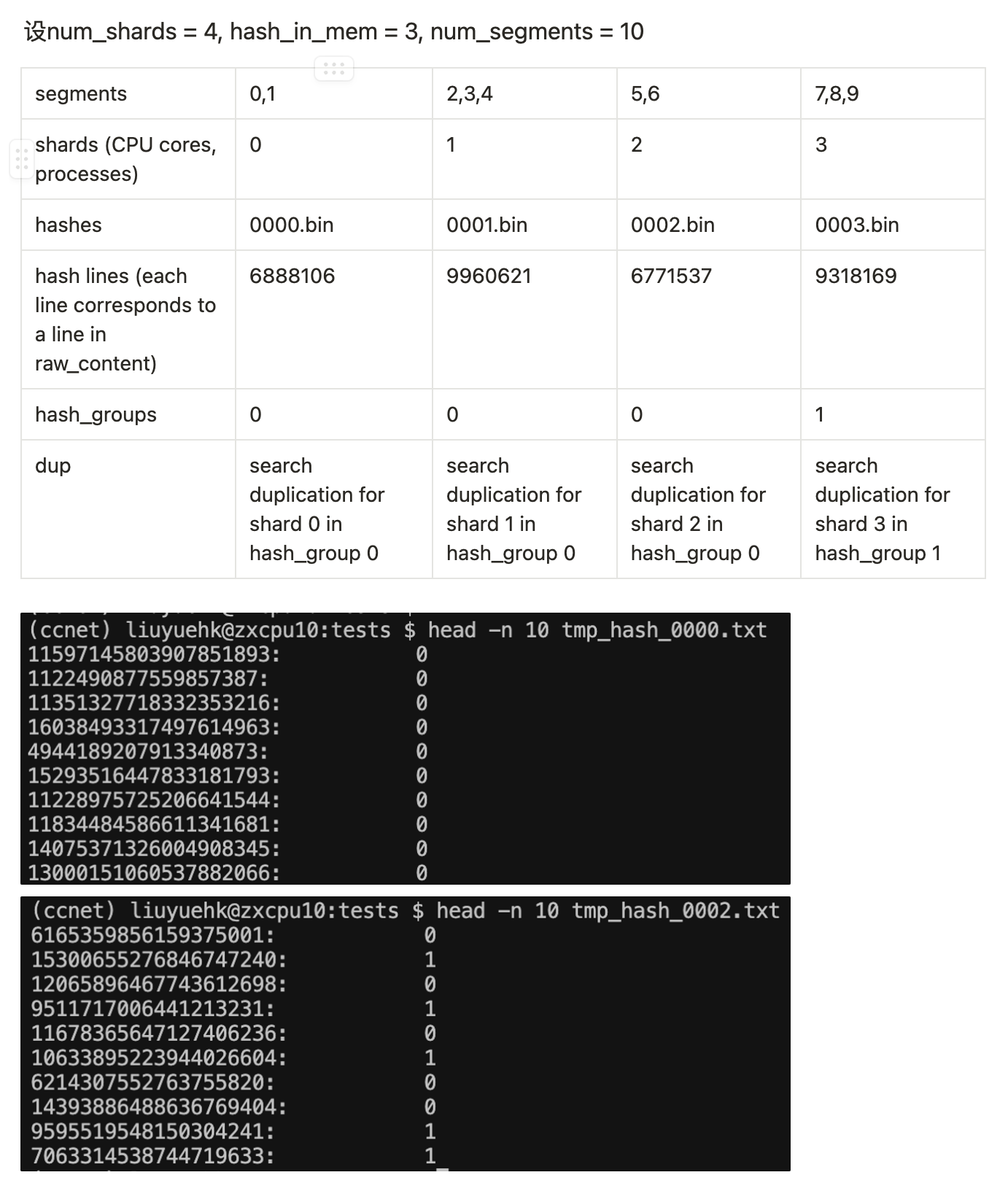
如上图所示,CCNet包含如下参数影响去重的效率和效果:
num_shards:表示将一个月的数据分成多少个块,同时表示在磁盘上存储多少个hash文件;hash_in_mem:去重时每个块独立进行;对于每个块,首先加载到磁盘上hash_in_mem个hash文件,然后删除该块的hash值出现在hash文件中出现$>1$次的段落;
可以看到,每个hash文件的格式是{截断的64位SHA1 Hash值:出现的次数-1}的词典格式。去重时首先加载词典到内存,然后检查待去重块的hash值对应的value,只保留value值为$0$的段落,即直接去除了所有重复的内容,没有保留一份。
语言识别
语言识别的目的是按语种将数据划分开。与前序工作类似,CCNet使用了fastText中的语言分类器。该语言分类器在Wikipedia、Tatoeba和SETimes数据上训练得到,使用n-gram作为输入特征,并使用层级Softmax输出。它支持176种语言,对输入的未知语种数据在每种语言上输出一个$[0,1]$之间的分数。在一个CPU核上每秒能处理1000段话。对于每个网页,CCNet计算一个最有可能的语言,以及分类器输出的语言分数。如果该分数超过$0.5$,就将网页划分到这个语言;在低于$0.5$时直接舍弃该网页。
质量筛选
经过去重和语言识别后仍然存在较低质量的语料。一种筛选高质量语料的方法是计算每个网页与目标域数据(如Wikipedia)的相似度。本文中,CCNet使用了一个在目标域上训练的语言模型,将评测模型的ppl值作为该网页的质量分数。
具体来说,首先在目标数据域上训练一个tokenizer和模型。本文使用了sentence-piece tokenizer和5-gram Kneser-Ney模型,主要看中该模型的高效性。接着,将待筛选的Common Crawl数据输入模型,计算每个段落的ppl值。ppl值越小,表示该段落与目标域越接近。执行完毕后,每种语言的数据被划分为高、中、低三种质量的数据。CCNet提供了他们在48种语言的Wikipedia上训练的5-gram模型、训练的代码以及划分质量等级的阈值。模型未涉及的语言不做质量筛选步骤。
实验
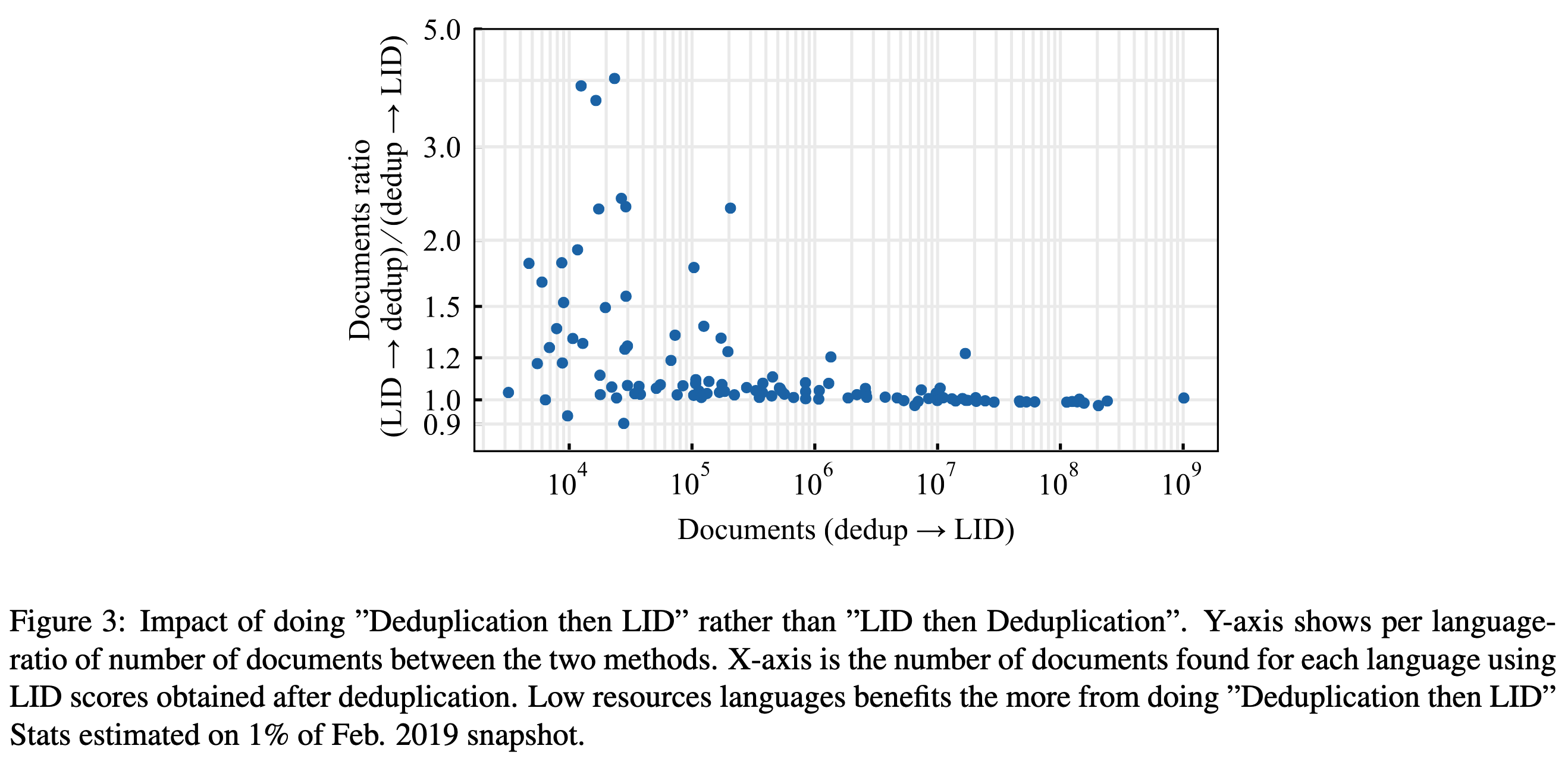
与前序工作不同,本文采用先去重(dedup)后语言识别(LID)的顺序,理由是去重可以去除一些网页中其他语言的噪声数据,如cookie等,这对数据量较少的语言尤其有效。上图中,横坐标表示去重+语言识别后段落的个数,纵坐标表示后去重和先去重两种方法分别剩余段落个数的比例,图中每个点对应一种语言。可以看到对于数据量较少(靠左)的语言,先去重能够去除更多的噪声段落。
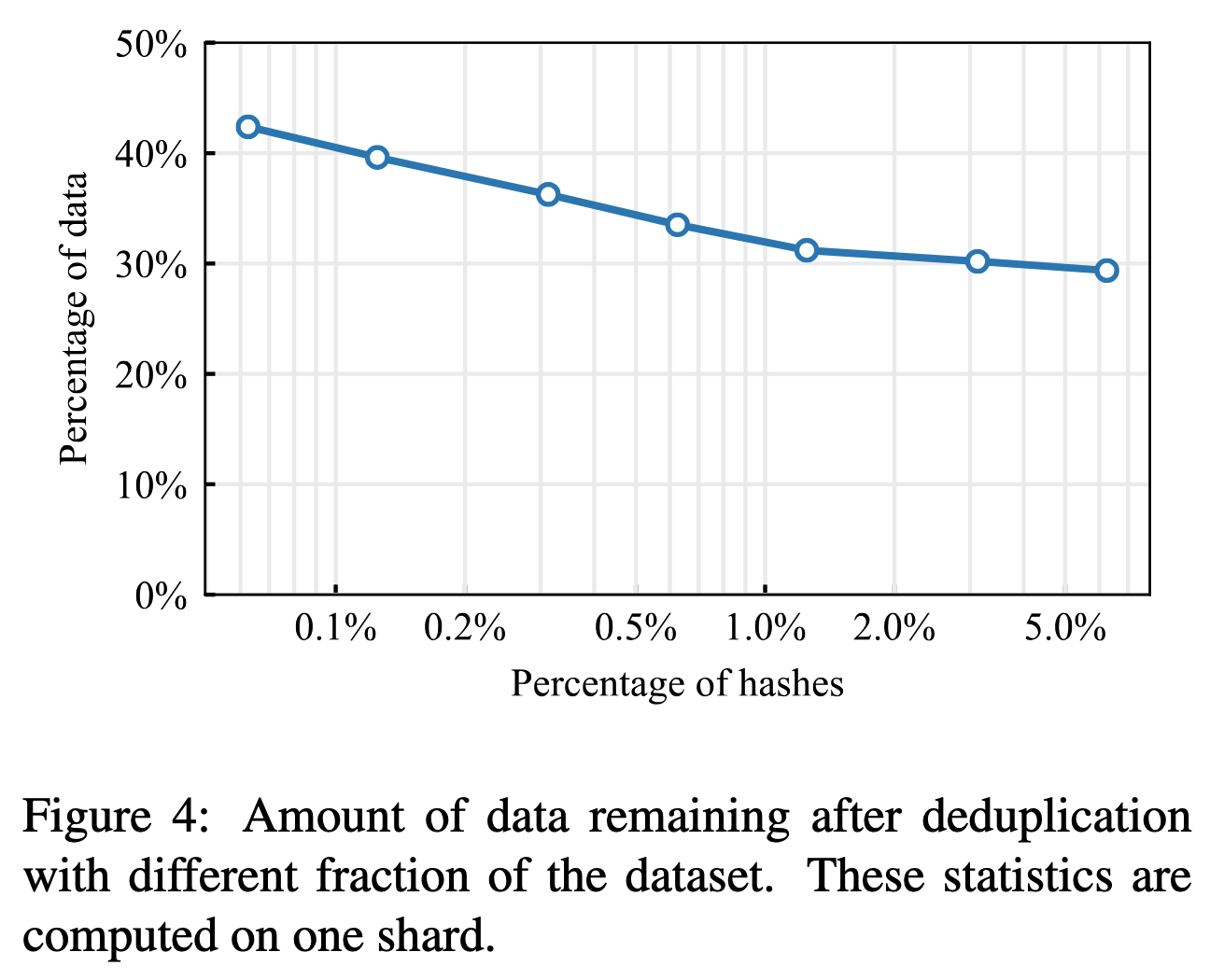
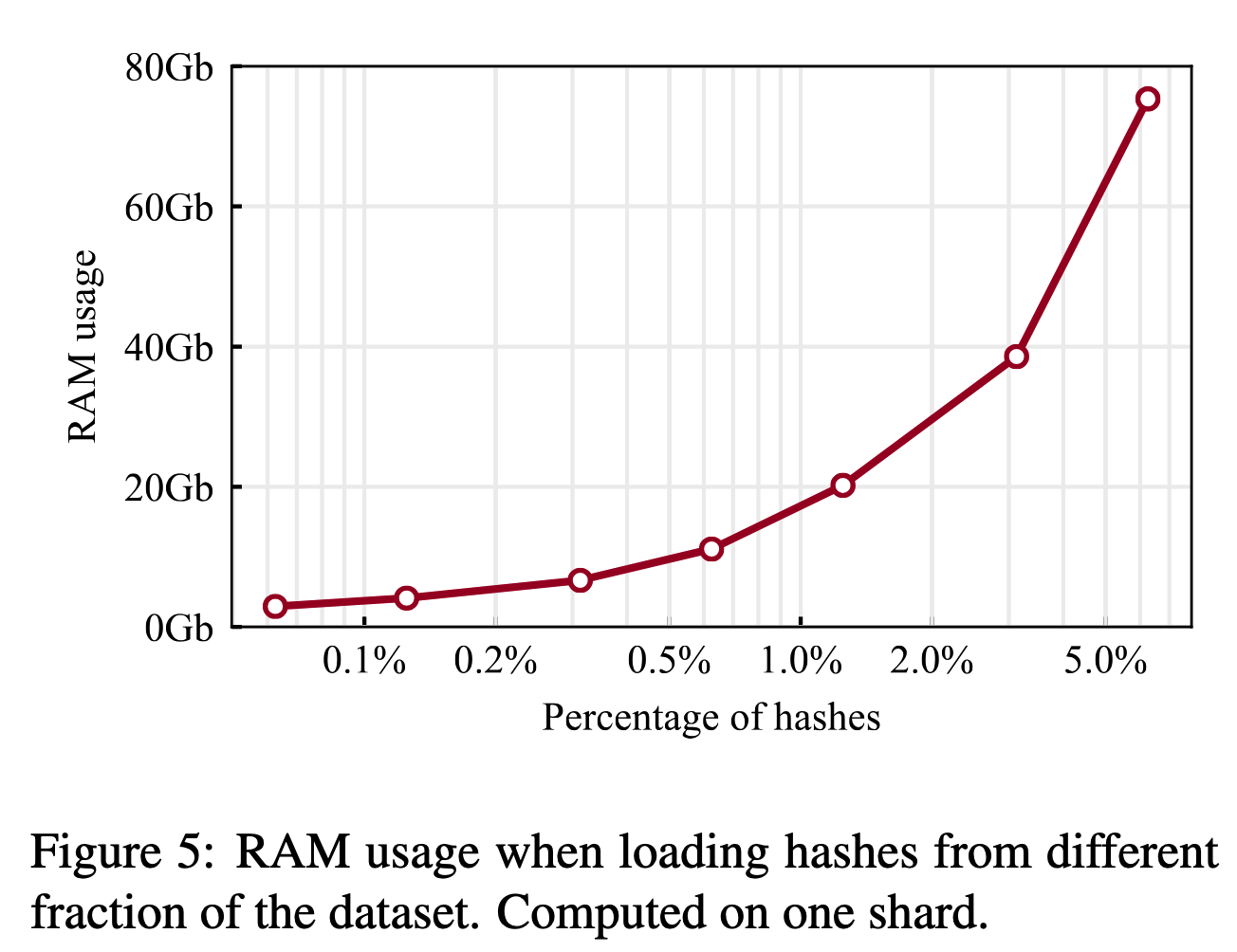
作者验证了hash_in_mem对去重效果和内存占用的影响。显然,hash_in_mem越大,去重时比较的范围越大,去重率越高,但同时内存的占用也会变高。CCNet使用了一种内存高效的词典,能够使用40GB的内存加载磁盘上13.5GB的Hash文件。
作者使用文字汇报了CCNet的时间效率。他们将一个月的数据划分成1600个块,对应于使用1600核的CPU,每块大约5GB。首先,CCNet边下载原数据边计算Hash值,在45min内完成。接着,去重花费40%的时间,语言识别划分12.5%的时间,tokenizer分词花费33%的时间,LM质量筛选花费13%的时间。最后,重新将剩余数据整理为每块5GB的大小。总的来说,CCNet花费9个小时清洗一个月的数据。