Recurrent Neural Network (RNN)
RNN介绍
回顾多层感知机网络,每个输入只对应一个输出。当输入的数据是一个序列,且序列中的元素与其他元素相关联时,就需要用到循环神经网络。例如,句子中的单词之间是相互关联的。
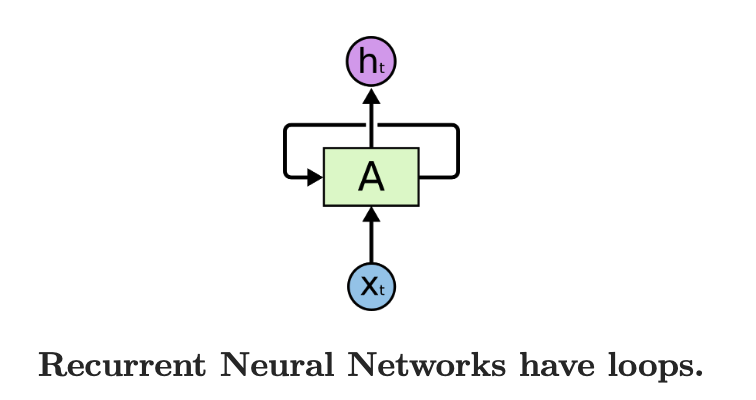
将其展开可以得到:
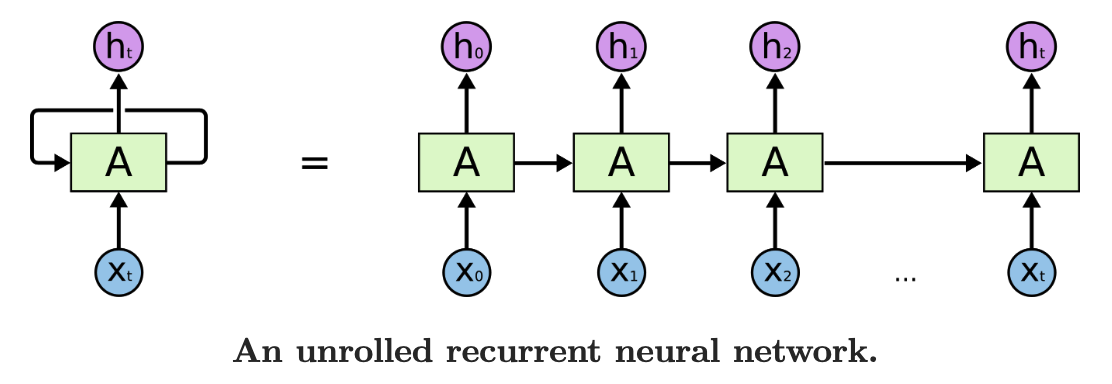
用公式表示为:
$$ \begin{aligned} f(x) &= Wx+b \\ h_0 &= \tanh(f(x_0)) \\ h_t &= \tanh(f(x_t)+f(h_{t-1})) \\ y_t &= \sigma(f(h_t)) \\ \end{aligned} $$
其中,$x_t,h_t,y_t$分别表示$t$时刻的输入、隐藏变量和输出。可以看到每个时间戳的隐藏态都利用了前一个隐藏态。尽管展开后模型图看起来更直观,但需要注意不同时间戳$t$之间的权重矩阵($W$)和偏移($b$)是共享的。
当叠加RNN层时,前一层的隐藏态$h_t$就作为当前层的输入$x_t$。
PyTorch.nn中的RNN层的输入和输出的时间戳相同。实际上,RNN结构可以应用于一对多、多对多、多对一等多种形式的问题。如下图所示。
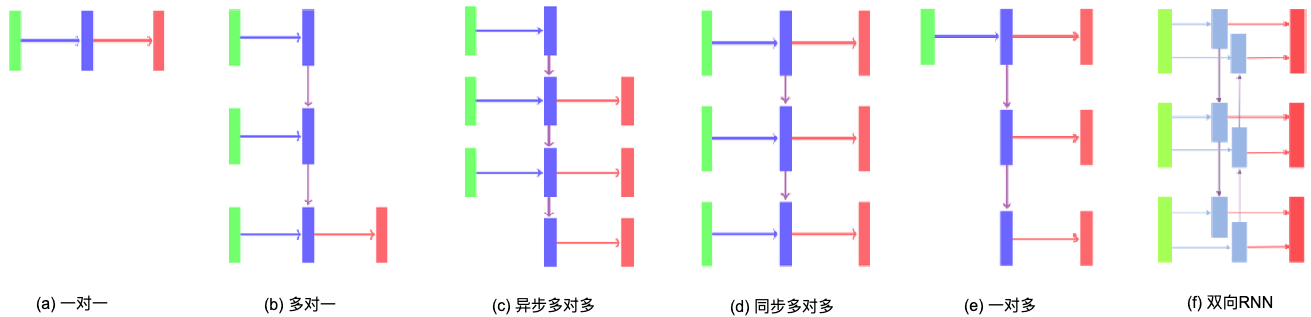
RNN的不足
使用RNN的一大挑战是长时依赖问题。例如,在文本生成任务中,如果输入这样一段话:
| |
其中<French>是带预测的单词。如果中间的...很长,那么该预测就需要根据很远之前的单词France判断,带来长时依赖问题。从理论上说,RNN能够解决这样的长时依赖问题,但现有的训练方法很难训练出这样的RNN(来源)。因此有了LSTM。
Long Short Term Memory networks (LSTM)
本节完全按照另一篇博客梳理。
LSTM背后的核心思想
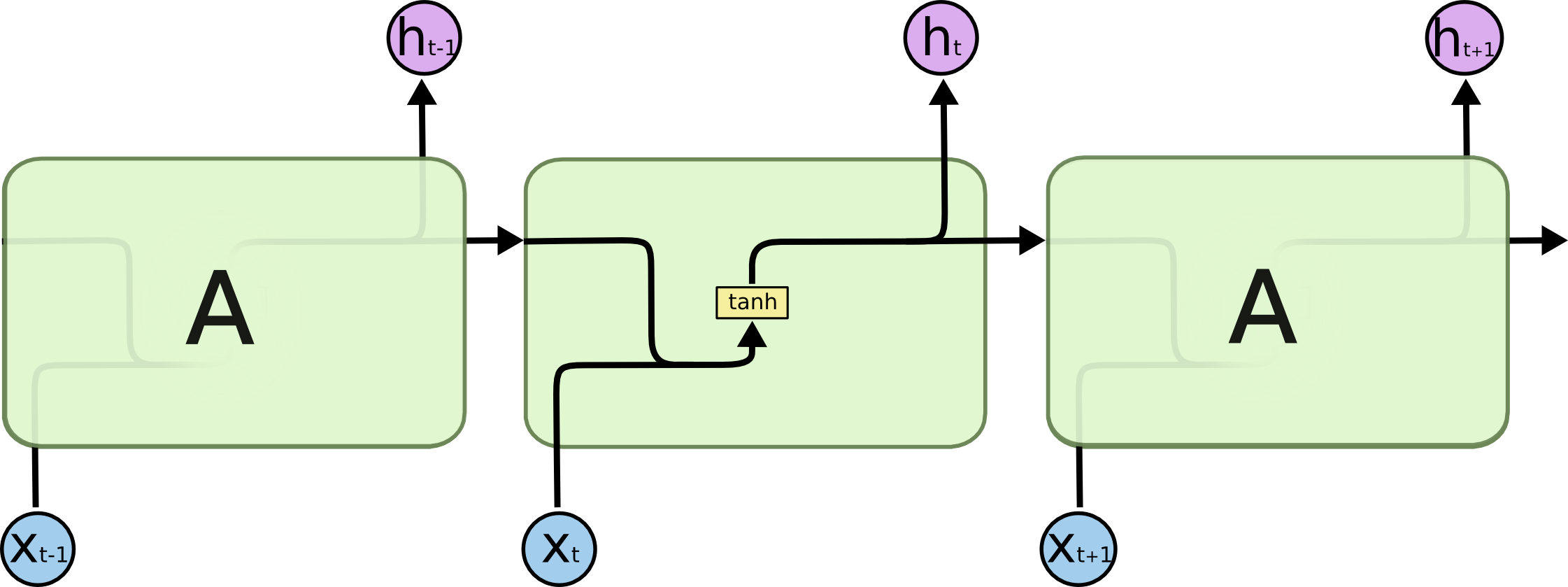
RNN中使用了非常简单的重复模块,即只有一个$\tanh$的非线性函数对上一时间戳的隐藏态和当前的输入进行聚合。如下图所示。
LSTM对重复模块做了细致的设计。如下图所示。
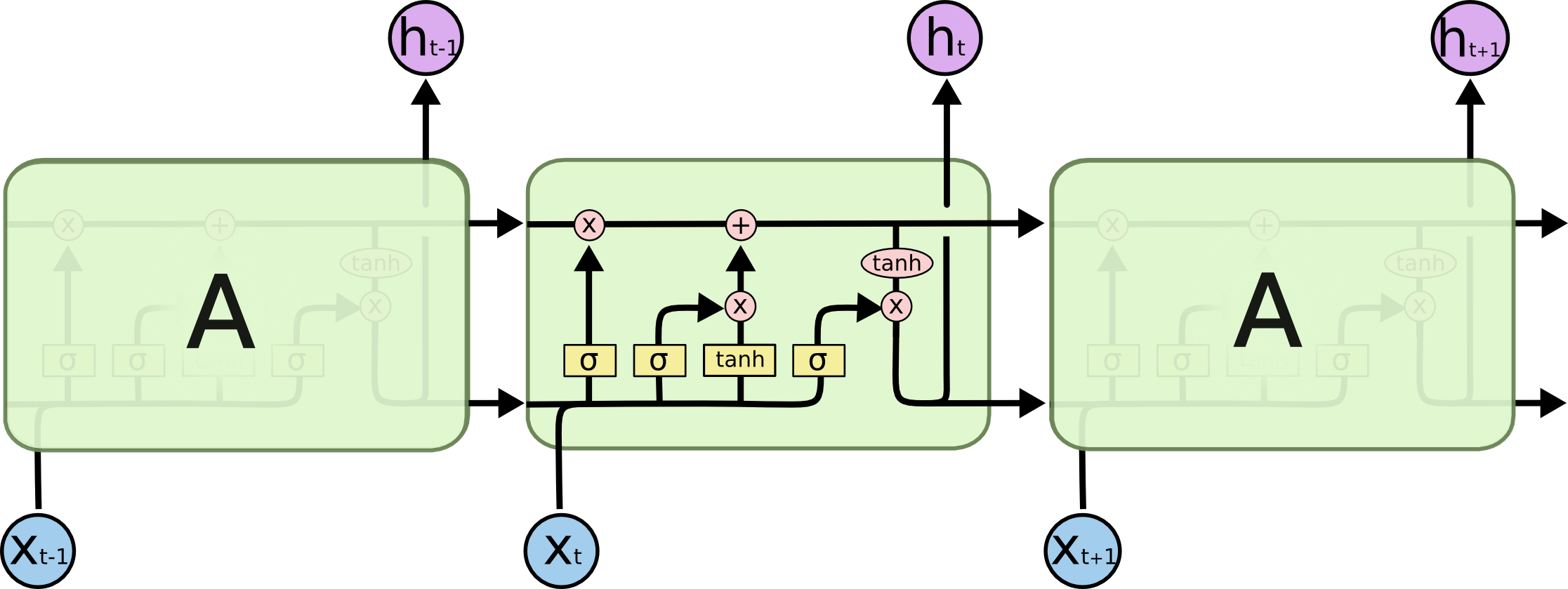
可以发现LSTM有3个输入,多出来的一个是一条“传送带”,它控制了忘记和记住前面时间戳的哪些信息。如下图所示。
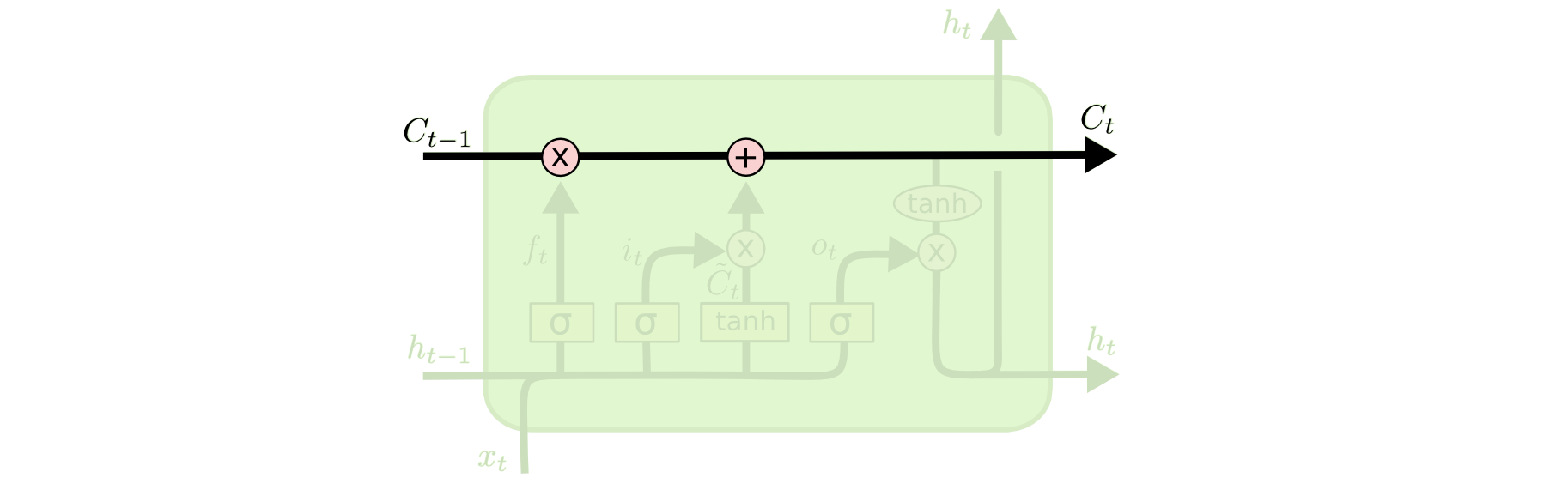
这种选择信息通过的机制叫做“门”(gate),通常由一个sigmoid层和一个点积操作组成。sigmoid函数的输出范围在0~1之间,当输出1时表示让所有信息通过,当输出0时表示拦截所有的信息。如下图所示。
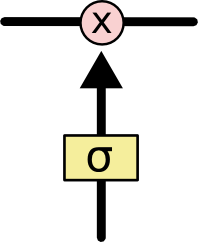
一步步搞懂LSTM
首先决定忘记或拦截哪些信息。LSTM通过上述门机制建模该操作。如下图所示。
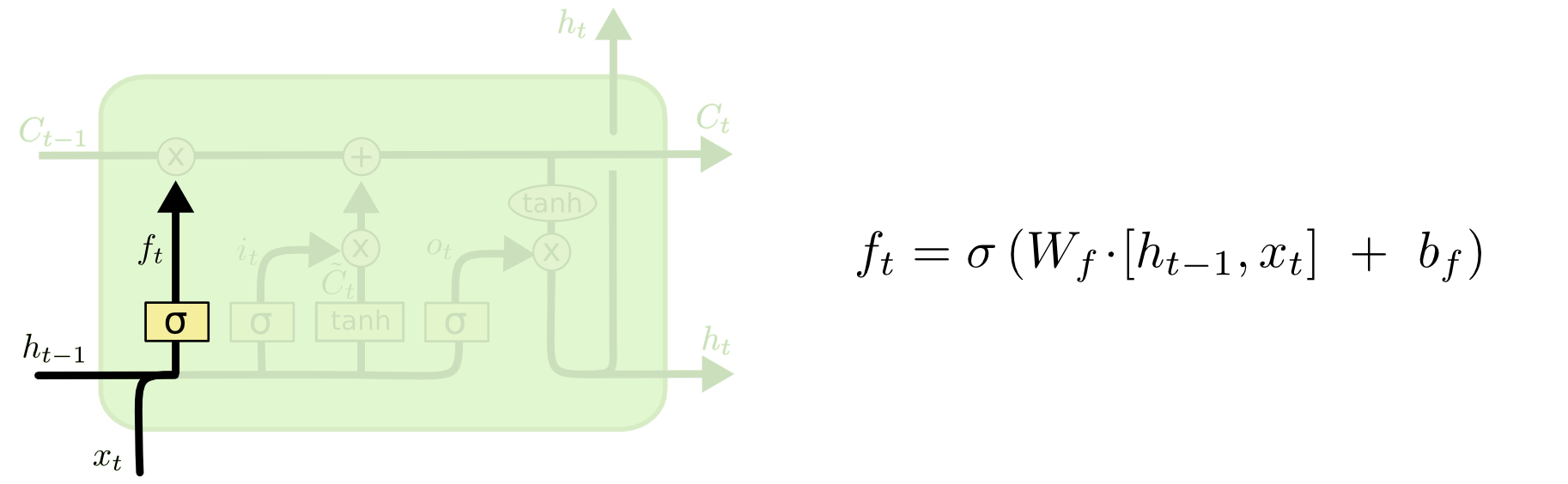
其中$\sigma$表示sigmoid函数,输出的$f_t$越大表示保留上一时间戳的$C_{t-1}$的信息越多。接着,决定从当前时间戳的输入数据$x_t$和上一时间戳的隐藏态$h_{t-1}$中保留多少信息,采用类似的门机制:
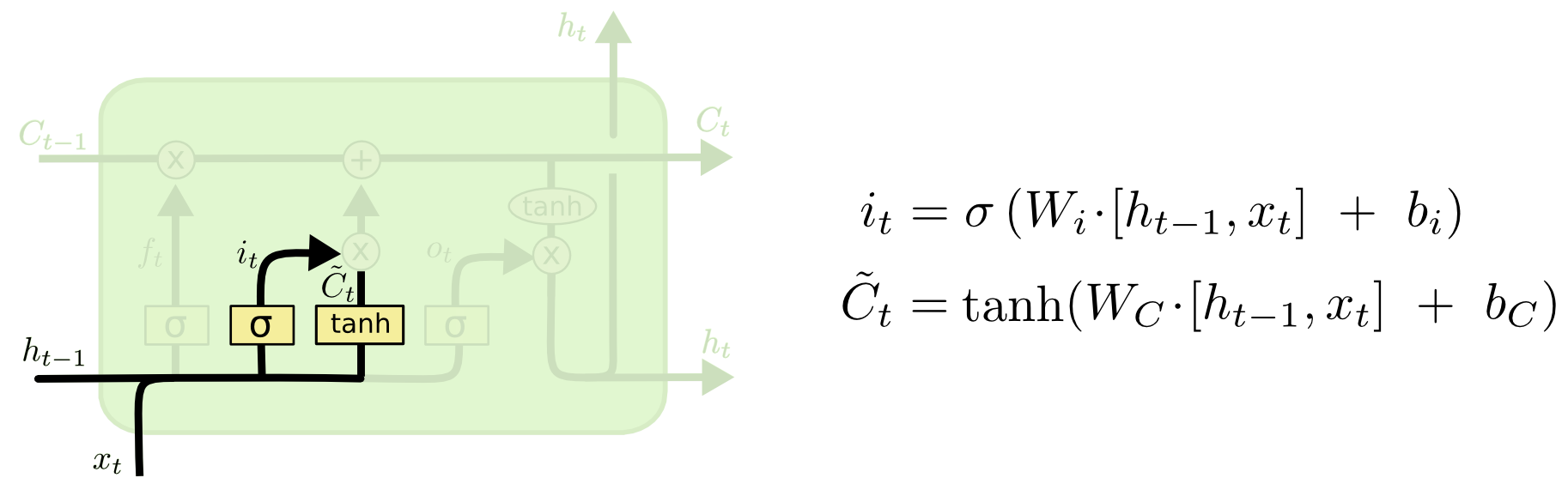
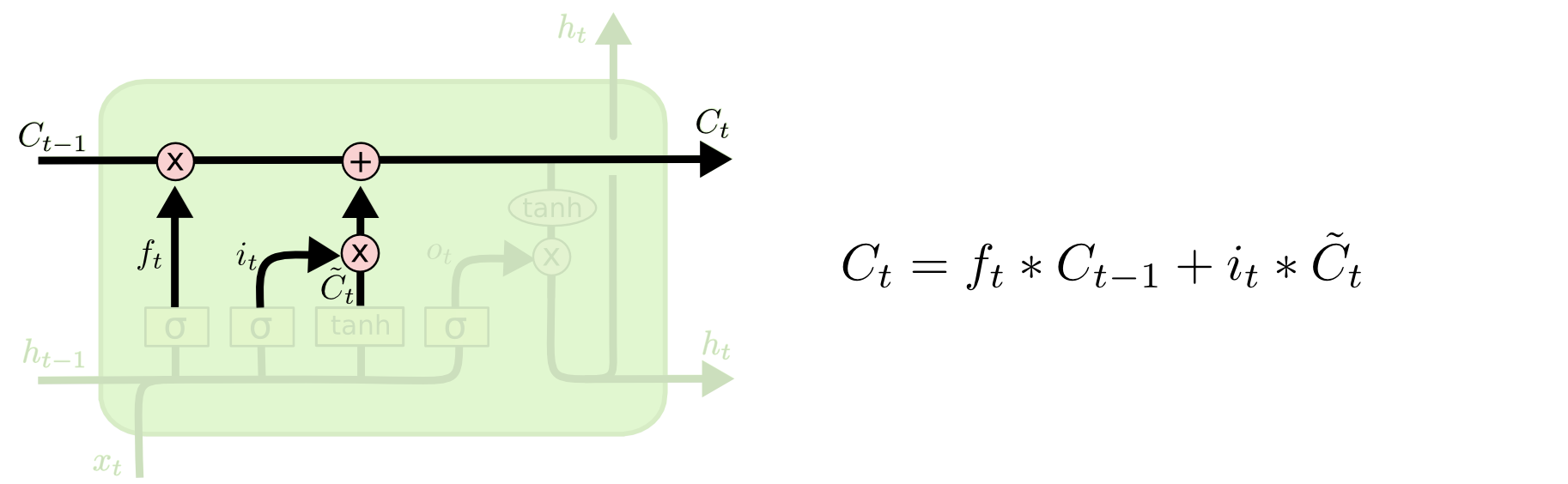
由上述两步操作就得到了当前时间戳的传送带的输出$C_t$:
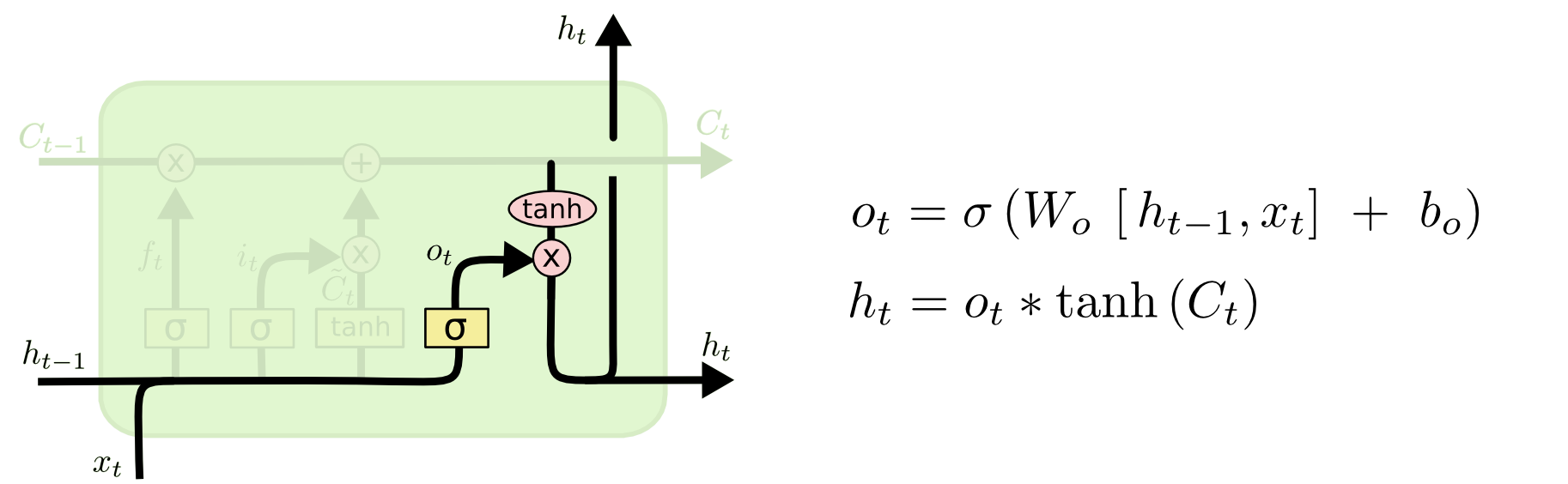
最后,决定当前时间戳的隐藏态的输出$h_t$,它基于传送带的输出$C_t$,但同样经过一个门操作:
Gated Recurrent Unit (GRU)
GRU对LSTM做了较大的修改,包括合并了传送带和隐藏态,并合并LSTM中拦截信息的门和通过信息的门为一个单独的门操作,称为“更新”门。GRU的优点是比LSTM简单,但取得了与LSTM相近的效果。如下图所示。
