本文基于 ( Citation: Karrer & Newman, 2011 Karrer, B. & Newman, M. (2011). Stochastic blockmodels and community structure in networks. Physical Review E, 83(1). 016107. https://doi.org/10.1103/PhysRevE.83.016107 ) 介绍社区发现中经典的随机块模型。 随机块模型是一种生成模型,它建模了社区与图生成之间的联系。尽管简单,随机块模型可以生成非常多样的图结构,包括同配图和异配图。
经典的随机块模型
考虑一个无向的多重图$G$,其中两个顶点之间的连边个数可以超过$1$。令$A_{ij}$表示图的邻接矩阵,当$i\neq j$时$A_{ij}$表示顶点$i$和$j$之间的连边个数,$i=j$时表示自环个数的2倍。 随机块模型假设不同边之间符合独立同泊松分布($P(x=k)=\frac{\lambda^k}{k!}\exp(-\lambda)$,期望为$\lambda$)。令$w_{rs}$表示社区$r$内的顶点和$s$内的顶点之间的期望连边个数,$\frac{1}{2}w_{rr}$表示社区$r$内部顶点之间的期望连边个数。令$g_i$表示顶点$i$的社区标签。拥有上述符号和独立性假设,我们可以写出图$G$的似然函数,即将所有边的存在概率相乘:
$$P(G|w,g)=\prod_{i<j}\frac{(w_{g_ig_j})^{A_{ij}}}{A_{ij}!}\exp(-w_{g_ig_j})\times \prod_i\frac{(\frac{1}{2}w_{g_ig_i})^{A_{ii}/2}}{(A_{ii}/2)!}\exp\left(-\frac{1}{2}w_{g_ig_i}\right)$$
做合并可以得到等价的表达:
$$P(G|w,g)=\frac{1}{\prod_{i<j}A_{ij}!\prod_i2^{A_{ii}/2}(A_{ii}/2)!}\prod_{rs}w_{rs}^{m_{rs}/2}\exp\left(-\frac{1}{2}n_rn_sw_{rs}\right)$$
其中$n_r$表示社区$r$内的顶点个数,$m_{rs}=\sum_{ij}A_{ij}\delta_{g_i,r}\delta_{g_j,s}$表示社区$r$和$s$之间的合计边个数,或者在$r=s$时等于该数值的二倍。
给定观测到的图结构,我们希望$w_{rs}$和$g_i$能够最大化这个似然函数。对似然函数取对数,并忽略掉与$w_{rs}$和$g_i$无关的常数(即前面带有$A_{ij}$的分式),得到:
$$\log P(G|w,g)=\sum_{rs}(m_{rs}\log w_{rs}-n_rn_sw_{rs})$$
首先对$w_{rs}$求导,$\frac{\partial \log P}{\partial w_{rs}}=\sum_{rs}\left(\frac{m_{rs}}{w_{rs}}-n_rn_s\right)=0$,得到$w$的最优解:
$$\hat{w}_{rs}=\frac{m_{rs}}{n_rn_s},\forall r,s$$
将$\hat{w}_{rs}$带回对数似然,得到$\log P(G|\hat{w},g)=\sum_{rs}m_{rs}\log(m_{rs}/n_rn_s)-2m$,其中$m=\frac{1}{2}\sum_{rs}m_{rs}$表示图中所有连边的个数,与$g_i$无关可以丢掉,因此可以得到最终的对数似然优化目标:
$$\mathcal{L}(G|g)=\sum_{rs}m_{rs}\log\frac{m_{rs}}{n_rn_s}$$
所以,随机块模型定义了一个对数似然。 接下来,我们可以使用各种方法从$K^N$空间中采样$g$,并取使得$\mathcal{L}$最大的$g$作为社区发现的输出。
采样方法(社区发现方法)
方法1
( Citation: Karrer & Newman, 2011 Karrer, B. & Newman, M. (2011). Stochastic blockmodels and community structure in networks. Physical Review E, 83(1). 016107. https://doi.org/10.1103/PhysRevE.83.016107 ) 中用自然语言描述了采样$g$的方法。首先随机地将图划分为$K$个社区(注意这里假设$K$是已知的)。接下来不断地将顶点移动到另一个使得$\mathcal{L}$增长最大的社区,或者减少最少的社区。当所有顶点移动一次后,检查移动过程中的$\mathcal{L}$值,取对应最大$\mathcal{L}$的移动结果作为下一次循环的开始状态。当$\mathcal{L}$无法被增长时算法停止。作者发现使用不同的随机种子多运行几次取最佳($\mathcal{L}$最大的结果?)能够得到最好的结果。
方法2
另一篇 ( Citation: Lu & Szymanski, 2019 Lu, X. & Szymanski, B. (2019). A Regularized Stochastic Block Model for the robust community detection in complex networks. Scientific Reports, 9(1). 13247. https://doi.org/10.1038/s41598-019-49580-5 ) 在Supplementary information中使用了另一种采样方法。初始时仍然是随机地将顶点指定到$K$个社区中的任意一个。接下来,尝试以一定的概率将顶点从社区$r$转移到社区$s$:
$$p(r\to s|t)=\frac{m_{ts}+\epsilon}{\sum_sm_{ts}+\epsilon K}$$
其中$t$表示随机采样的一个邻居的社区标签 ( Citation: Peixoto, 2014 Peixoto, T. (2014). Efficient Monte Carlo and greedy heuristic for the inference of stochastic block models. Physical Review E, 89(1). 012804. https://doi.org/10.1103/PhysRevE.89.012804 ) ,$m_{ts}$表示社区$t$和$s$之间的合计边个数,或者在$t=s$时等于该数值的二倍。$\epsilon>0$通常被设置成较小的数值,在$\epsilon$趋于无穷时转化概率变为$1/K$成为完全随机地转移。对于每次尝试转移,接受该转移的概率$a$定义为:
$$a=\min \left\{\exp(\beta\Delta\mathcal{L})\frac{\sum_tn_tp(s\to r|t)}{\sum_tn_tp(r\to s|t)},1\right\}$$
其中转移完成后该顶点有$n_t$个邻居属于社区$t$,$\Delta\mathcal{L}$表示每次转移后对数似然的变化,$p(s\to r|t)$在顶点进行$r\to s$的转移后进行计算。$\beta$是温度参数,可以防止陷入局部最优(Supplementary information中的式子疑似有误,比如$\min$函数里没有$1$,没有温度参数,根据 ( Citation: Peixoto, 2014 Peixoto, T. (2014). Efficient Monte Carlo and greedy heuristic for the inference of stochastic block models. Physical Review E, 89(1). 012804. https://doi.org/10.1103/PhysRevE.89.012804 ) 进行了修改)。
随机块模型与模块度的联系
随机块模型的优化目标是对数似然,而一些热门的社区发现算法,如Louvain方法 ( Citation: Blondel, Guillaume & al., 2008 Blondel, V., Guillaume, J., Lambiotte, R. & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008(10). P10008. https://doi.org/10.1088/1742-5468/2008/10/P10008 ) 等,采用模块度 ( Citation: Newman & Girvan, 2004 Newman, M. & Girvan, M. (2004). Finding and evaluating community structure in networks. Physical Review E, 69(2). 026113. https://doi.org/10.1103/PhysRevE.69.026113 ) 作为优化目标。对数似然和模块度实际上存在联系。
将随机块模型的对数似然式子等价变换,得到
$$\mathcal{L}(G|g)=\sum_{rs}\frac{m_{rs}}{2m}\log\frac{m_{rs}/2m}{n_rn_s/n^2}$$
上式中仅添加了顶点个数$n$和边个数$m$,对于优化来说没有影响。式中有两个概率表达式:$m_{rs}/2m$和$n_rn_s/n^2$。其中,$m_{rs}/2m$表示随机采样一条边落在社区$r$和$s$之间的概率;$n_rn_s/n^2$可以看作当图中有$n^2/2$条边时的这个概率。将上述两个概率分布分别记作$p_K(r,s)$和$p_1(r,s)$,则对数似然可以被重写为
$$\mathcal{L}(G|g)=\sum_{rs}p_K(r,s)\log\frac{p_K(r,s)}{p_1(r,s)}$$
成为$p_K$和$p_1$的KL-散度。
这种定义一个空模型(null model)$p_1$的思想在模块度中也有体现:
$$Q(g)=\frac{1}{2m}\sum_{ij}[A_{ij}-P_{ij}]\delta(g_i,g_j)$$
其中$A_{ij}$表示邻接矩阵在$i,j$处的值,$P_{ij}$表示在空模型下这个值的期望。如果在模块度中使用对数似然的空模型$p_1$,那么模块度的表达式转化为:
$$Q(g)=\sum_{r=1}^K[p_K(r,r)-p_1(r,r)]$$
然而,$p_1$的最大问题是不符合实际观测到的图结构,它没有保护观测图中的顶点的度,因此实际应用中通常不会使用。如果能够保证空模型中顶点度的期望与观测图相同,那么新的空模型可以表示为
$$p_{degree}(r,s)=\frac{\kappa_r}{2m}\frac{\kappa_s}{2m}$$
其中$\kappa_r=\sum_sm_{rs}=\sum_ik_i\delta_{g_i,r}$表示社区$r$中所有顶点的度之和。(也可以从另一角度理解$\kappa_r$:将原图中所有的边切成两半准备重新随机连接,那么$\kappa_r$表示从社区$r$中伸出的半边(stub)的个数。)这样新的模块度转化为:
$$Q(g)=\sum_{r=1}^K[p_K(r,r)-p_{degree}(r,r)]$$
新的空模型$p_{degree}$导出的模块度优化目标的效果更好。这是因为具有高度数的顶点本就应有更高的概率相连,因为它们能伸出更多的半边。
受模块度的启发,作者 ( Citation: Karrer & Newman, 2011 Karrer, B. & Newman, M. (2011). Stochastic blockmodels and community structure in networks. Physical Review E, 83(1). 016107. https://doi.org/10.1103/PhysRevE.83.016107 ) 提出将顶点度的异构性集成到对数似然中,能得到更好的随机块模型。
度保护随机块模型
在经典的随机块模型中,使用$w_{g_ig_j}$刻画社区$g_i$和$g_j$之间边的期望个数,没有对社区$g_i$和$g_j$内的顶点进行区分。在新的度保护随机块模型中,引入新的变量$\theta$,其中$\theta_i$控制顶点$i$的平均度数,这样对一个观测到的图$G$,新的似然函数为:
$$P(G|\theta,w,g)=\prod_{i<j}\frac{(\theta_i\theta_jw_{g_ig_j})^{A_{ij}}}{A_{ij}!}\exp(-\theta_i\theta_jw_{g_ig_j})\times \prod_i\frac{(\frac{1}{2}\theta_i^2w_{g_ig_i})^{A_{ii}/2}}{(A_{ii}/2)!}\exp\left(-\frac{1}{2}\theta_i^2w_{g_ig_i}\right)$$
其中$\theta_i$作了归一化:$\sum_i\theta_i\delta_{g_i,r}=1$。这样$\theta_i$不再表示顶点$i$度数的期望,而是表示当一条边连向社区$g_i$时,具体连向这个顶点$i$的概率。与经典随机块模型类似,对似然函数进行等价重写:
$$P(G|\theta,w,g)=\frac{1}{\prod_{i<j}A_{ij}!\prod_i2^{A_{ii}/2}(A_{ii}/2)!}\prod_i\theta_i^{k_i}\prod_{rs}w_{rs}^{m_{rs}/2}\exp\left(-\frac{1}{2}w_{rs}\right)$$
其中$k_i$表示顶点$i$的度数。由于$\theta_i$作了归一化,$\exp$函数内不再包含$n_rn_s$。对似然函数取对数,并忽略掉与变量无关的常数:
$$\log P(G|\theta,w,g)=2\sum_ik_i\log\theta_i+\sum_{rs}(m_{rs}\log w_{rs}-w_{rs})$$
首先观察到对数似然关于$\theta_i$是递增函数,而$\theta_i$有归一化限制,且$\theta_i>0$,因此$\theta_i$的极值点为
$$\hat{\theta}_i=\frac{k_i}{\kappa_{g_i}}$$
然后对$w$求偏导,得到$w_{rs}$的极值点为
$$\hat{w}_{rs}=m_{rs}$$
将$\hat{\theta}_i$和$\hat{w}_{rs}$代入对数似然中,得到
$$\log P(G|\theta,w,g)=2\sum_ik_i\log\frac{k_i}{\kappa_{g_i}}+\sum_{rs}m_{rs}\log m_{rs}-2m$$
作者利用$\kappa_r=\sum_sm_{rs}=\sum_ik_i\delta_{g_i,r}$对第一项做了巧妙的等价变换:
$$\begin{aligned} 2\sum_ik_i\log\frac{k_i}{\kappa_{g_i}} &= 2\sum_ik_i\log k_i-2\sum_ik_i\log \kappa_{g_i} \\ &= 2\sum_ik_i\log k_i-2\sum_i\sum_rk_i\delta_{g_i,r}\log \kappa_r \\ &= 2\sum_ik_i\log k_i-2\sum_r\sum_ik_i\delta_{g_i,r}\log \kappa_r \\ &= 2\sum_ik_i\log k_i-2\sum_r\kappa_r\log\kappa_r \\ &= 2\sum_ik_i\log k_i-(\sum_r\kappa_r\log\kappa_r+\sum_s\kappa_s\log\kappa_s) \\ &= 2\sum_ik_i\log k_i-(\sum_{rs}m_{rs}\log\kappa_r+\sum_{sr}m_{rs}\log\kappa_s) \\ &= 2\sum_ik_i\log k_i-\sum_{rs}m_{rs}\log\kappa_r\kappa_s \end{aligned}$$
代入对数似然中,并丢弃与$g$无关的常数($k_i,m$),得到:
$$\mathcal{L}(G|g)=\sum_{rs}m_{rs}\log\frac{m_{rs}}{\kappa_r\kappa_s}$$
可以看到,经过推导新的对数似然与经典的对数似然只有很小的差别。但是新的对数似然已经转化为$p_K$和$p_{degree}$的KL-散度,即
$$\mathcal{L}(G|g)=\sum_{rs}\frac{m_{rs}}{2m}\log\frac{m_{rs}/2m}{(\kappa_r/2m)(\kappa_s/2m)}$$
换句话说,新的对数似然找到的是与给定顶点度的随机图差别最大的社区划分,而经典的对数似然找到的是与完全随机图差别最大的社区划分。
生成图结构
随机块模型是生成模型,除了利用给定的图拟合它的参数,还可以人为指定参数来合成新的图 ( Citation: Karrer & Newman, 2011 Karrer, B. & Newman, M. (2011). Stochastic blockmodels and community structure in networks. Physical Review E, 83(1). 016107. https://doi.org/10.1103/PhysRevE.83.016107 ) 。
对于随机块模型,我们需要输入$g\in\mathbb{Z}_+^n,w\in\mathbb{R}_+^{K\times K},\theta\in\mathbb{R}_+^n$,分别表示社区、社区之间连边个数的期望、当一条边指向一个顶点所在的社区时,指定到该顶点的概率。其中,$g$主要确定了社区的个数,以及每个社区的规模,可以按需求随意设定,也可以由输入的每个社区的规模转化而来(如按顶点序号从小到大);$\theta_i=\frac{k_i}{\kappa_{g_i}}$,因此可以先指定每个顶点的度$k_i$,进而确定$\theta$;$w$需要满足$\sum_{s}w_{rs}=\kappa_r$。因此,输入参数的导出关系是$g\to\theta\to w$。
对于$w$,我们可以进一步增加随机因素,使生成的图结构更加多样。将上面人工指定的$w$记作$w^{planted}$。另一种随机生成的$w^{random}$为$w^{random}_{rs}=\frac{\kappa_r\kappa_s}{2m}$。这样最终输入的$w$为
$$w_{rs}=\lambda w_{rs}^{planted}+(1-\lambda)w_{rs}^{random}$$
其中$\lambda\in[0,1]$为超参。一旦指定了$g,w,\theta$,模型首先依照均值为$w_{rs}$(在$r=s$时均值为$\frac{1}{2}w_{rs}$)的泊松分布生成社区之间实际连边个数的矩阵$m_{rs}$,再根据$\theta$选取每条连边的端点,这样就生成了图结构。再结合$g$就得到了带顶点社区标签的合成图。
( Citation: Karrer & Newman, 2011 Karrer, B. & Newman, M. (2011). Stochastic blockmodels and community structure in networks. Physical Review E, 83(1). 016107. https://doi.org/10.1103/PhysRevE.83.016107 ) 列举了一些$w^{planted}$的例子:
$$ w^{planted}= \begin{bmatrix} \kappa_1 & 0 & 0 & 0 \\ 0 & \kappa_2 & 0 & 0 \\ 0 & 0 & \kappa_3 & 0 \\ 0 & 0 & 0 & \kappa_4 \\ \end{bmatrix} $$
表示社区结构。
$$ w^{planted}= \begin{bmatrix} \kappa_1-\kappa_2 & \kappa_2 \\ \kappa_2 & 0 \\ \end{bmatrix} $$
其中$\kappa_1\ge\kappa_2$。当$\kappa_1\simeq\kappa_2$时表示二部图结构。
$$ w^{planted}= \begin{bmatrix} \kappa_1-A & A & 0 \\ A & \kappa_2-A & 0 \\ 0 & 0 & \kappa_3 \\ \end{bmatrix} $$
其中$A\le\min(\kappa_1,\kappa_2)$为常数。
正则随机块模型
研究者发现 ( Citation: Lu & Szymanski, 2019 Lu, X. & Szymanski, B. (2019). A Regularized Stochastic Block Model for the robust community detection in complex networks. Scientific Reports, 9(1). 13247. https://doi.org/10.1038/s41598-019-49580-5 ) 在拟合度保护随机块模型时,模型可能随机地收敛到同配或异配的社区结构,这可能不是数据挖掘用户所期望的。因此,作者提出用一个参数来限定随机块模型的输出。
前置实验
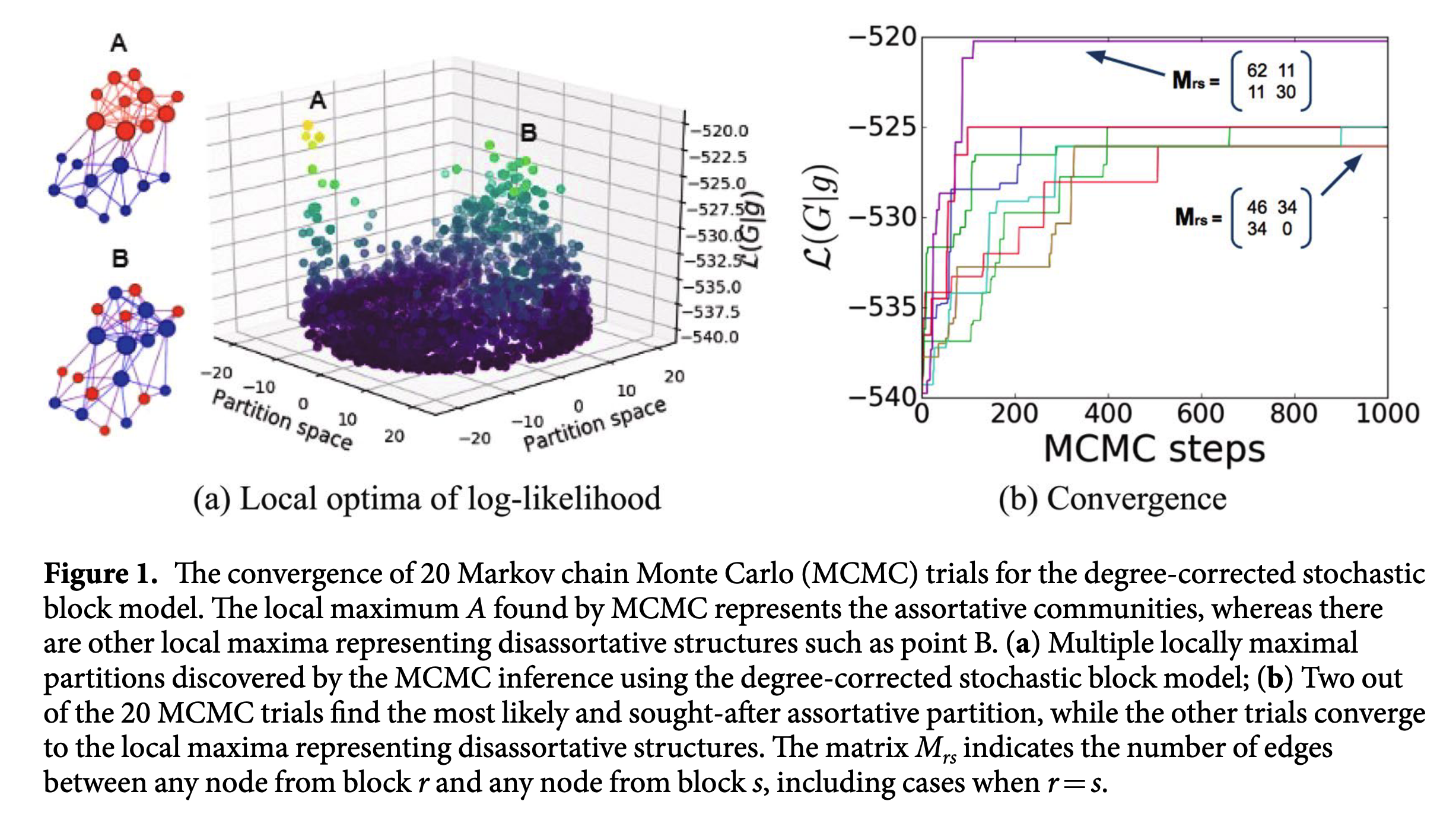
作者做了一个实验。首先使用度保护随机块模型生成一个图,其中
$$w_{rs}= \begin{cases} \gamma w_0, & \text{if } r=s \\ w_0, & \text{if } r\neq s \end{cases} $$
其中$\gamma$越大会生成结构越同配(assortative)的图结构,$w_0$控制了图的稀疏程度。实验中,$\gamma$取$10$,$w_0$取$0.01$,顶点度序列$\{k_i\}$由参数为$2.5$的幂律分布生成,社区个数为$2$,每个社区包含$10$个顶点。使用MCMC方法(采样方法2)进行采样。在$20$次采样中,模型只有$1$次收敛到同配的局部最优解,其余$19$次均收敛到异配的局部最优解。如下图所示。
改进方法
回顾度保护随机块模型中,泊松分布的均值定义为$\lambda_{ij}=\theta_i\theta_jw_{g_ig_j}$。作者将其重新定义为
$$\lambda_{ij}= \begin{cases} w_{g_ig_j}I_iI_j, & \text{if } g_i=g_j \\ w_{g_ig_j}O_iO_j, & \text{if } g_i\neq g_j \end{cases} $$
回顾对数似然$\log(G|\{\lambda_{ij}\})=\frac{1}{2}\sum_{ij}(A_{ij}\log\lambda_{ij}-\lambda_{ij})$,代入新定义的$\lambda_{ij}$,得到
$$ \begin{align} \mathcal{L}(G|g,w,I,O) &= \sum_{g_i=g_j}(A_{ij}\log(w_{g_ig_j}I_iI_j)-w_{g_ig_j}I_iI_j)+\sum_{g_i\neq g_j}(A_{ij}\log(w_{g_ig_j}O_iO_j)-w_{g_ig_j}O_iO_j)\\ &= \left[\sum_{g_i=g_j}A_{ij}(\log I_i+\log I_j)+\sum_{g_i\neq g_j}A_{ij}(\log O_i+\log O_j)\right]+\left[\sum_{g_i=g_j}A_{ij}w_{g_ig_j}+\sum_{g_i\neq g_j}A_{ij}w_{g_ig_j}\right]-\left[\sum_{g_i=g_j}w_{g_ig_j}I_iI_j+\sum_{g_i\neq g_j}w_{g_ig_j}O_iO_j\right]\\ &= 2\sum_i(k_i^+\log I_i+k_i^-\log O_i)+\sum_{rs}m_{rs}\log w_{rs}-w_{rs}\Lambda_{rs} \\ \end{align} $$
其中$k_i^+$表示节点$i$在其社区内部的度,$k_i^-=k_i-k_i^+$,$\Lambda_{rs}$为
$$\Lambda_{rs}= \begin{cases} (\sum_{i\in r}I_i)^2, & \text{if } r=s \\ \sum_{i\in r}O_i\sum_{j\in s}O_j, & \text{if }r\neq s \end{cases} $$
其中$i\in r$表示$g_i=r$。
计算$w_{rs}$的极值,即$\frac{\partial \mathcal{L}}{\partial w_{rs}}=\frac{m_{rs}}{w_{rs}}-\Lambda_{rs}=0$,得到$\hat{w}_{rs}=\frac{m_{rs}}{\Lambda_{rs}}$,代入对数似然,得到
$$\mathcal{L}(G|g,I,O)=\sum_{rs}m_{rs}\log\frac{m_{rs}}{\Lambda_{rs}}+2\sum_i(k_i^+\log I_i+k_i^-\log O_i)$$
定义一个先验参数$f_i=\frac{I_i}{I_i+O_i}$,$\theta_i=I_i+O_i$,那么上述对数似然可以重写为
$$\mathcal{L}(G|g,I,O)=\sum_{rs}m_{rs}\log\frac{m_{rs}}{\Lambda_{rs}}-2\sum_ik_iH(\frac{k_i^+}{k_i},f_i)+2\sum_ik_i\log\theta_i$$
其中$H(\frac{k_i^+}{k_i},f_i)=-\frac{k_i^+}{k_i}\log f_i-\frac{k_i^-}{k_i}\log(1-f_i)$表示观测到的$\frac{k_i^+}{k_i}$与先验$f_i$的交叉熵。因此,最大化该对数似然也是在最小化观测和先验的差距。$\frac{k_i^+}{k_i}$表示顶点$i$连接同社区邻居个数占其所有邻居个数的比例。
假设先验函数$f$只与顶点度有关,即$f_i=f(k_i)$,那么$f(k):\mathbb{Z}_+\to[0,1]$应是严格递减的函数。对于同配的社区划分,我们有
- $f(1)=1$,因为只有一个邻居的顶点一定属于它连接的那个社区;
- 对于$k\approx|V|$,有$f(k)\ll 1$,因为一个中心顶点最终不归属于任何社区。
作者给出了$f$的一些例子,如
- $f(k)=\alpha+\frac{1-\alpha}{k}$,
- $f(k)=\max\{f, \frac{1}{k}\}$。
实验
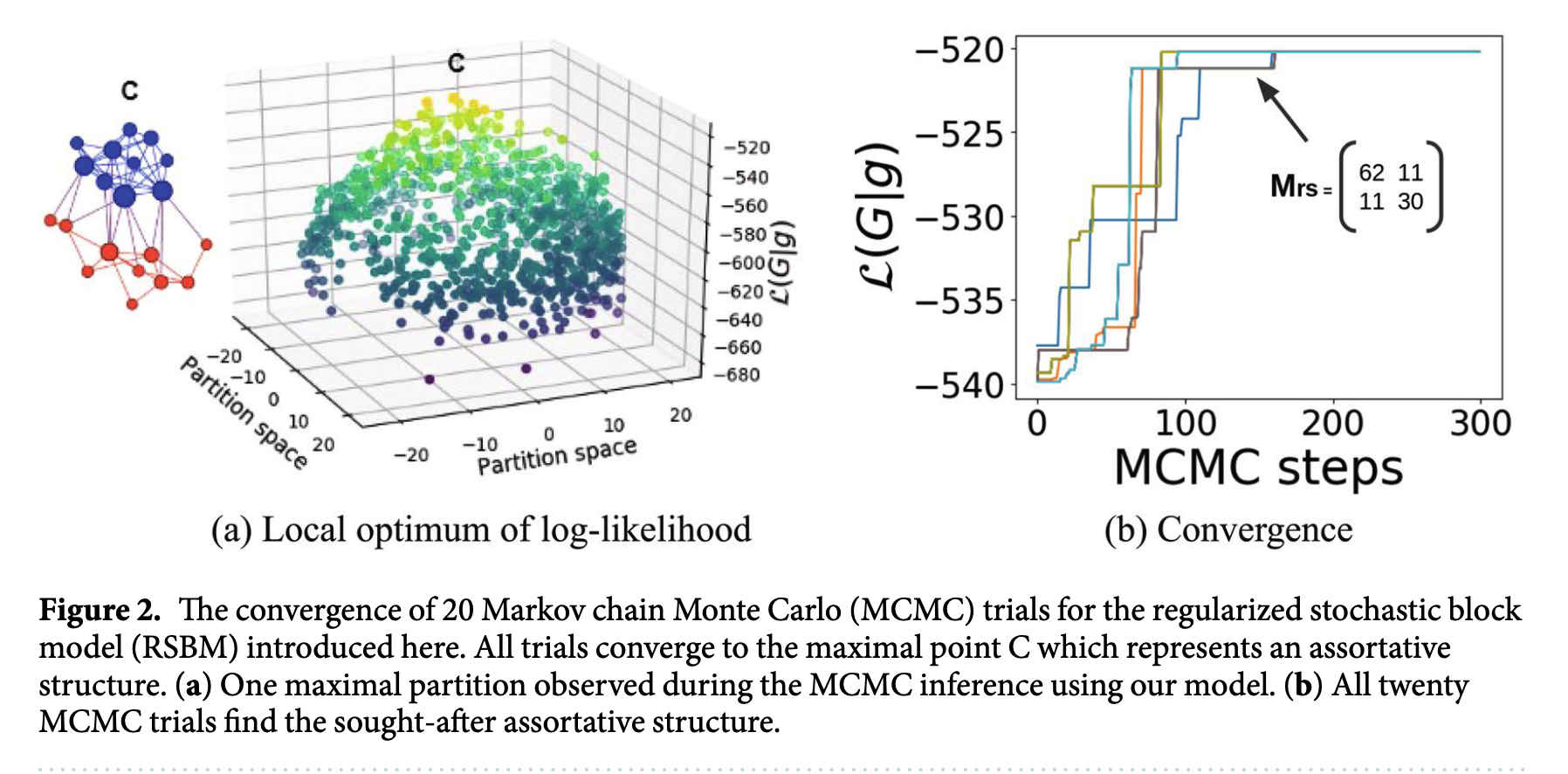
首先是之前的$20$个顶点的合成数据集的对比。可以发现使用正则随机块模型后,$20$次MCMC均收敛到同配的社区结构。
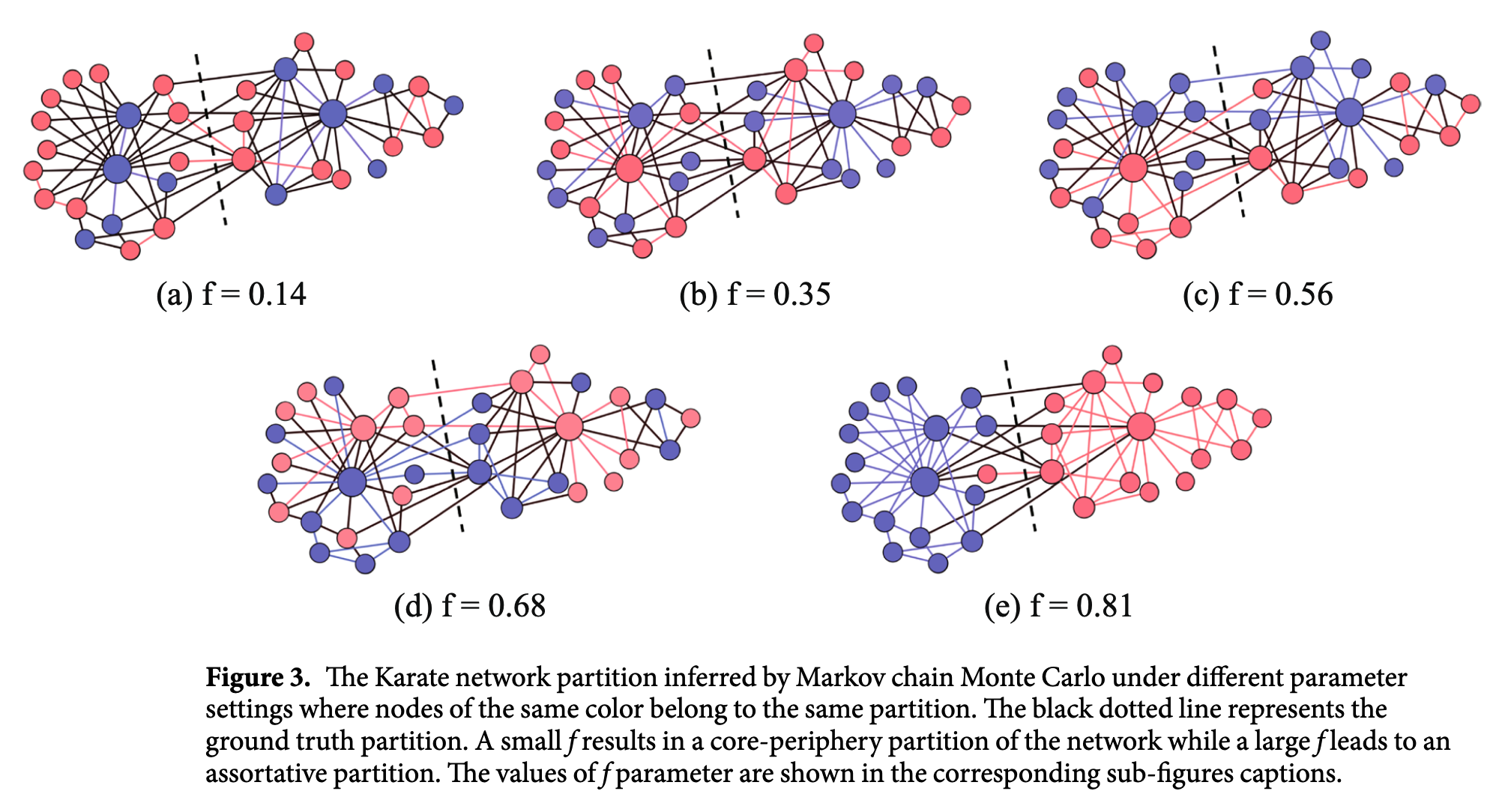
在Karate club network 真实数据集上,设定$\theta_i=k_i,f(k_i)=\max\{f, \frac{1}{k_i}\}$。使用不同的$f$可以控制输出社区的同配性。如下图所示。
RSBM的性质
定理1:当对于任意顶点$i$,$f_i=1/2$时,RSBM的MLE与DCSBM的MLE相同。
定理2:对于任意自定义的$\{f_i\}$和极大似然估计的结果$\hat{\theta}_i$,RSBM能够保护顶点的度,即
$$\sum_j\lambda_{ij}=k_i$$
定理3:当对于任意顶点$i$,$\theta_i=k_i$时,最大化RSBM的对数似然等价于最大化
$$\mathcal{L}=D_{KL}(p_{degree}(r,s)||p_{null}(r,s))-2\mathbb{E}_{k_i}[H(\frac{k_i^+}{k_i})]$$
EM算法
基于维基百科梳理EM算法(Expectation–Maximization)。EM算法是一种估计模型参数的方法。
问题定义
给定数据集$X$,一个参数为$\theta$的统计模型,统计模型假设$X$由隐变量$Z$生成。那么,数据集$X$的似然函数可以表示为
$$L(\theta;X)=p(X|\theta)=\int p(X,Z|\theta)dZ=\int p(X|Z,\theta)p(Z|\theta)dZ$$
直接最大化$L(\theta;X)$是不可行的,因为隐变量$Z$是未知的,得到$Z$之前需要先知道模型参数$\theta$。
EM算法流程
EM算法分为两步:E步和M步。
- E步:给定当前模型参数的估计$\theta^{(t)}$,定义
$$Q(\theta|\theta^{(t)})=E_{Z\sim p(\cdot|X,\theta^{(t)})} [\log p(X,Z|\theta)]$$
- M步:计算$\theta$使其最大化$Q(\theta|\theta^{(t)})$,即
$$\theta^{(t+1)}=\text{argmax}_{\theta} [Q(\theta|\theta^{(t)})]$$
可以看到,EM算法由优化MLE的目标$L(\theta;X)$改为优化$Q(\theta|\theta^{(t)})$。可以证明优化$Q(\theta|\theta^{(t)})$时$L(\theta;X)$也在被优化。
EM算法正确性的证明
由贝叶斯定理,
$$\log p(X|\theta)=\log p(X,Z|\theta)-\log p(Z|X,\theta)$$
由$E[f(x)]=\sum p(x)f(x)$,在等式两边对Z求期望,左边对Z是常数,得
$$ \begin{align} \log p(X|\theta) &=\sum_Zp(Z|X,\theta^{(t)})\log p(X,Z|\theta)-\sum_Zp(Z|X,\theta^{(t)})\log p(Z|X,\theta) \\ &= Q(\theta|\theta^{(t)})+H(\theta|\theta^{(t)}) \end{align}\label{eq:1}\tag{1} $$
代入$\theta=\theta^{(t)}$,得
$$ \begin{align} \log p(X|\theta^{(t)})=Q(\theta^{(t)}|\theta^{(t)})+H(\theta^{(t)}|\theta^{(t)}) \end{align}\label{eq:2}\tag{2} $$
($\ref{eq:1}$)式减($\ref{eq:2}$)式,得
$$\log p(X|\theta)-\log p(X|\theta^{(t)})=Q(\theta|\theta^{(t)})-Q(\theta^{(t)}|\theta^{(t)})+H(\theta|\theta^{(t)})-H(\theta^{(t)}|\theta^{(t)})$$
注意到
$$ \begin{aligned} H(\theta|\theta^{(t)})-H(\theta^{(t)}|\theta^{(t)}) &=-\sum_Zp(Z|X,\theta^{(t)})\log\frac{p(Z|X,\theta)}{p(Z|X,\theta^{(t)})} \\ &= KL(p(Z|X,\theta^{(t)}) || p(Z|X,\theta)) \\ &\ge 0 \end{aligned} $$
因此$\log p(X|\theta)-\log p(X|\theta^{(t)})\ge Q(\theta|\theta^{(t)})-Q(\theta^{(t)}|\theta^{(t)})$,即MLE的似然至少增长了EM算法增长的数值。
Core-periphery 随机块模型
( Citation: Gallagher, Young & al., 2021 Gallagher, R., Young, J. & Welles, B. (2021). A clarified typology of core-periphery structure in networks. Science Advances, 7(12). eabc9800. https://doi.org/10.1126/sciadv.abc9800 ) 梳理了针对当前core-periphery的两种定义,分别定义并开源了探测两种core-periphery结构的随机块模型。本文引用了图数据集合:The KONECT Project。
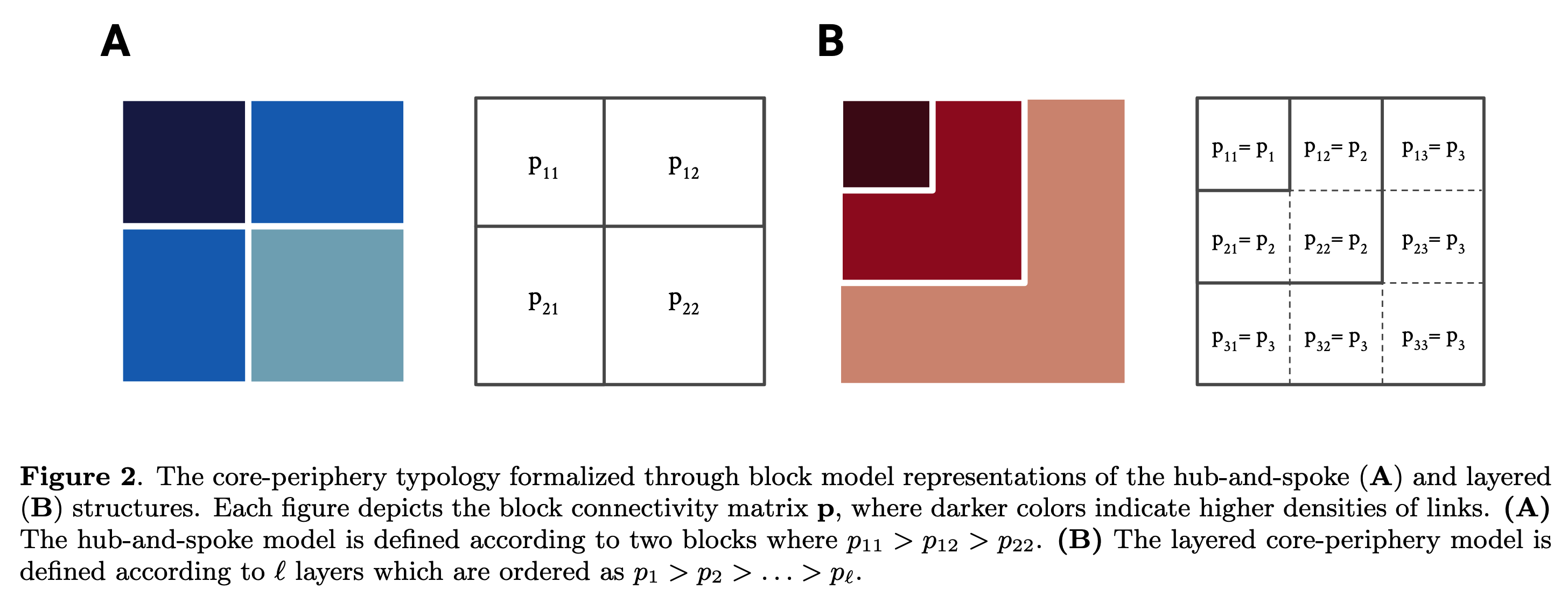
Core-perphery是图上一类基础而重要的子结构,顾名思义由紧密相连的"core"核心节点和稀疏的"periphery"边缘节点构成。可用于建模在线放大、认知学习过程、技术基础设施组织和重要疾病传播通道。检测core-periphery结构的方法包括统计推断、谱分解、扩散映射、图形模式计数、测地线追踪和模型平均。尽管方法多样,现有方法未形成对core-periphery的统一定义。主要分为两类:
- 中心辐射型(hub-and-spoke)结构,即将图分成两个块,分别为核心块和边缘块。核心块中的顶点相互连接,核心节点与一些边缘节点相连,而边缘节点之间没有连边;
- $k$-核分解(layered)结构,即将图层级划分为多个$k$-核。
实际应用时可能难以获知算法到底返回的是那种core-periphery结构。本文首先分别利用流行的中心辐射结构和层级核结构的挖掘算法,在多个真实图数据集上运行,并定量衡量两种结果的差异。接着,将两种结构都建模成随机块模型,定义模型选择方法。最后以一个案例分析结束本文。
两种结构的差异
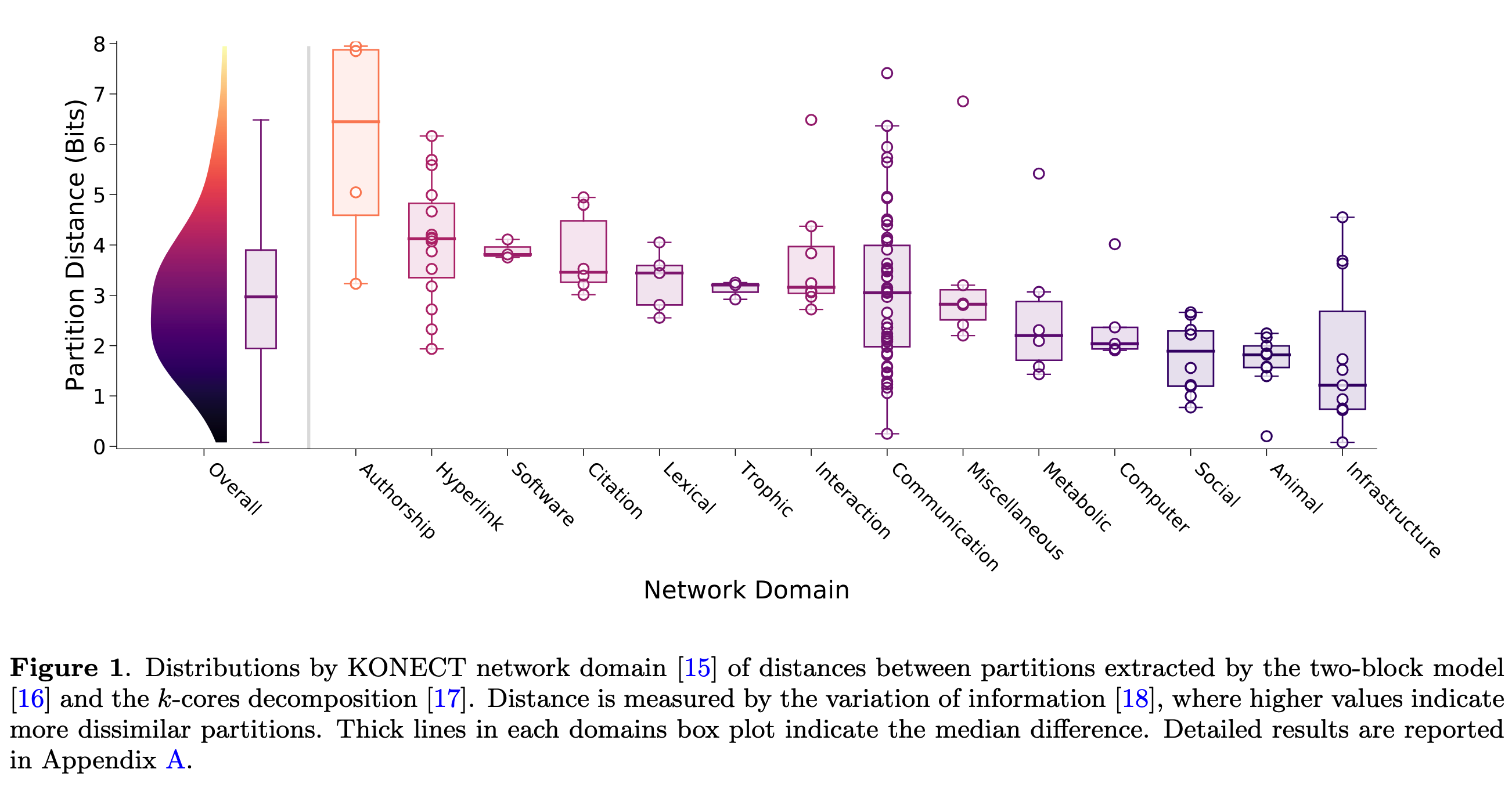
KONECT(Kolbenz Network Collection)是一个图数据集的仓库,涵盖了社交、生物、技术等多领域的图数据。对每张图,使用两种算法 ( Citation: Lip, 2011 Lip, S. (2011). A Fast Algorithm for the Discrete Core/Periphery Bipartitioning Problem. https://doi.org/10.48550/arXiv.1102.5511 ; Citation: Batagelj & Zaversnik, 2003 Batagelj, V. & Zaversnik, M. (2003). An O(m) Algorithm for Cores Decomposition of Networks. https://doi.org/10.48550/arXiv.cs/0310049 ) 分别挖掘出中心辐射结构和层级结构。接着,利用VI(varaition of information)评估两种结构的距离。VI越大差异越大。结果如下图所示。
方法简介
为了研究哪种结构对特定的图有更好的统计描述,作者使用贝叶斯随机块模型将它们联系起来。随机块模型的观点是,两点之间的连边概率完全由它们所属的块之间连边概率决定。 由贝叶斯定理,块划分$g$和块之间的连边概率$w$的后验概率与它们的先验与似然的乘积正相关(proportional),$A$表示邻接矩阵。
$$ P(g,w|A) \propto P(A|g,w)P(g)P(w) $$
欲构建core-periphery随机块模型,需要形式化先验$P(w)$,使其符合core-periphery结构的定义。如上面的Figure 2所示,两种结构分别对应不同的$P(w)$:
- 中心辐射型:原始定义$p_{11}=p_{12}=1,p_{22}=0$,本文考虑宽泛的情形:$p_{11}>p_{12}>p_{22}$;
- $k$-核分解:$p_1=p_{11}>p_2=p_{12}=p_{22}>p_3=p_{13}=p_{23}=p_{33}>\cdots$
按照上述定义,先验矩阵可以表示为:
- 中心辐射型:$P(w)\propto \pmb{1}_{\{0<p_{22}<p_{12}<p_{11}<1\}}$
- $k$-核分解:$P(w)\propto \pmb{1}_{\{0<p_l<p_{l-1}<\cdots<p_1<1\}}$
其中,$\pmb{1}_{\star}$在$\star$条件被满足时值为1,否则为0。
接着,使用Gibbs采样拟合随机块模型,得到两种结构的块:$g_H,g_L$,分别表示中心辐射(hub-and-spoke)结构和层级核分解(layered)结构。
得到两种结构后,需要评估哪一个对于图$A$是更好的拟合,通过后验概率的比值:
$$ \Lambda=\frac{P(g_H,H|A)}{P(g_L,L|A)} $$
其中$H,L$分别表示两种结构对应的随机块模型。$\Lambda>1$表示中心辐射型的结构更好。 现在假设对于两种模型没有偏好,即先验$P(H)=P(L)=1/2$,由$P(g_H,H|A)=P(g_H,A|H)P(H)/P(A)\propto P(g_H,A|H)$,可以等价计算
$$ \begin{align} -\log\Lambda &= \Sigma_H-\Sigma_L \\ &= -\log P(A,g_H|H)+\log P(A,g_L|L) \end{align} $$
其中$\Sigma_M=-\log P(A,g_M|M)$称作模型M的描述长度(description length),表示模型模型压缩信息的能力。能够使用更少的描述长度描述一个图网络的模型是更好的模型。因此,$\Sigma_M$越小表示模型越好。
总的来说,在一张图上,通过不同的算法可以挖掘出相应的辐射型结构和层级结构。作者先用随机块模型统一了挖掘两种结构的算法框架,接着定义了一种比较两种结构优劣的参量。
方法细节
KONECT数据仓库
KONECT包含了261个不同领域的网络数据,包括无向、有向、二部图,图中可能包含多重边、自环、无权边、有权边、符号边和带有时序信息的边。本文对其进行了如下预处理操作:
- 忽略边上的权重,多重边转化为普通的单重边;
- 忽略自环;
- 去除边的方向;
- 只保留图上的最大弱连通分量。
除此之外,本文去除了数据仓库中的时序图、不完整图和二部图。最后剩余142个图。其中有95个图拥有超过200k个顶点。
随机块模型的细节
回顾随机块模型的后验分布:
$$ P(g,w|A) \propto P(A|g,w)P(g)P(w) $$
社区之间边个数矩阵$w$的先验分布定义为:
$$ \begin{align} P_H(w) &= 3!\cdot \pmb{1}_{\{0<w_{22}<w_{12}<w_{11}<1\}} \\ P_L(w) &= l!\cdot \pmb{1}_{\{0<w_l<w_{l-1}<\cdots<w_1<1\}} \end{align} $$
其中前面的常数$3!,l!$用于正则化?
社区划分$g$的无偏好先验分布 ( Citation: Peixoto, 2019 Peixoto, T. (2019). Bayesian stochastic blockmodeling. (pp. 289–332). Retrieved from http://arxiv.org/abs/1705.10225 ) 定义为:
$$ P(g)=\frac{\prod_r n_r!}{N!}{N-1 \choose l-1}^{-1}N^{-1} $$
似然定义为:
$$ P(A|g,w) = \prod_{r\le s}w_{rs}^{m_{rs}}(1-w_{rs})^{M_{rs}-m_{rs}} $$ 其中$m_{rs},M_{rs}$分别表示社区$r$和$s$之间的实际边数和最大可能边数,$N$表示顶点个数,$l$表示社区个数。如果令$n_r$表示社区$r$内顶点的个数,那么有
$$ M_{rs}= \begin{cases} n_rn_s, r\neq s \\ n_r(n_r-1)/2, r=s \end{cases} $$
作者以挖掘$k$-核分解的随机块模型为例,阐述拟合该随机块模型的算法:
- 采样$P(g|A,w)$。 在每一步MCMC,随机挑选一个顶点$i$,随机生成它的新社区标签$g_i’$,以如下概率接受该转移:
$$ a = \min\left(1,\frac{P(g’|A,w)}{P(g|A,w)}\frac{P(g|g’)}{P(g’|g)}\right) $$
其中,在随机转换社区的情况下,$P(g_i’|g)=\frac{1}{l}$。后验概率$P(g|A,w)\propto P(A|g,w)P(g)$。与前面的极大似然方法不同,这里使用极大后验的优化目标,通过贝叶斯定理引入人为的先验。
- 采样$P(w|A,g)$。 作者假设$w$中每个元素是独立的。这样,有如下推导:
$$ \begin{align} P(w|A,g)&=\frac{P(g,w|A)}{P(g|A)}\propto P(A|g,w)P(w) \\ P(w|A,g)&=P(w_1,w_2,\cdots,w_l|A,g)=P(w_s|A,g,w_{-s})P(w_{-s}|A,g) \\ P(w_s|A,g,w_{-s})&\propto P(A|w,g)P(w) \\ P(w_s|A,g,w_{-s})&\propto w_s^{\alpha_s}(1-w_s)^{\beta_s}\pmb{1}_{0<w_l<\cdots<w_1<1} \end{align} $$
其中$\alpha_s=\sum_{r\le s}m_{rs},\beta_s=\sum_{r\le s}M_{rs}-m_{rs}$。 这表示$P(w_s|A,g,w_{-s})$服从截断的$\text{Beta}(\alpha_s+1,\beta_s+1)$分布。 作者阐述了从该分布采样的方法。