Variational Autoencoders
原博主为Lilian Weng
与简单的自编码器不同,变分自编码器的表征$\mathbf{z}$是一个分布。 给定一个数据集$\mathbf{X}=\{\mathbf{x}_i\}_{i=1}^N$,变分自编码器的观点是$\mathbf{x}$由一个隐变量$\mathbf{z}$产生,而$\mathbf{z}$则遵循一个先验分布,通常取正态分布。 因此,变分自编码器可以由3个概率分布刻画:
- $p(\mathbf{z})$: 先验分布
- $p(\mathbf{x}|\mathbf{z})$: 解码器
- $p(\mathbf{z}|\mathbf{x})$: 后验分布,编码器
其中后验分布很难直接计算,因此自编码器从一个未训练过的编码器,即对后验分布的估计$q(\mathbf{z}|\mathbf{x})$开始,通过优化目标函数不断逼近$q(\mathbf{z}|\mathbf{x})$和$p(\mathbf{z}|\mathbf{x})$的距离。
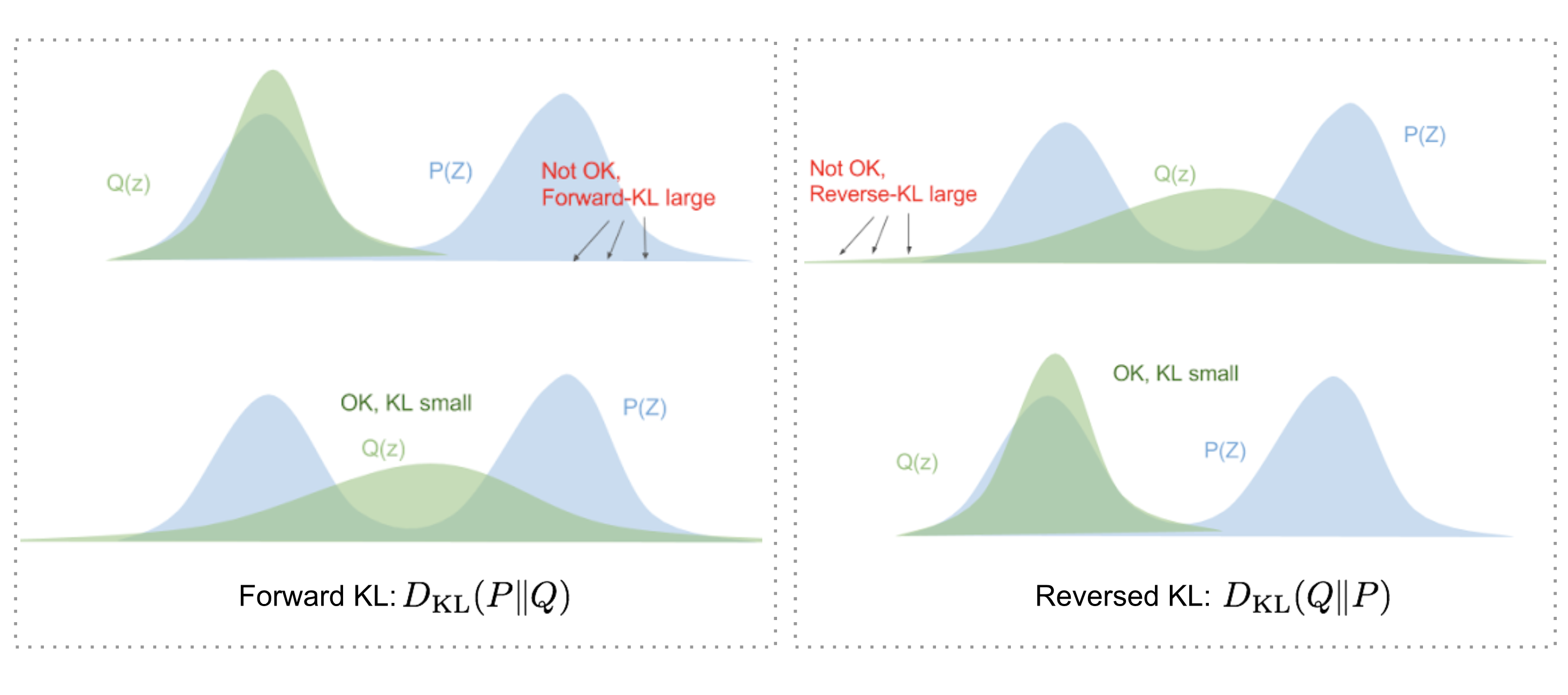
这里使用KL散度衡量两个分布的距离,即$D_{KL}(q(\mathbf{z}|\mathbf{x})||p(\mathbf{z}|\mathbf{x}))$。注意KL散度不具有对称性,原博主Lilian Weng甚至指出了为什么不使用$D_{KL}(p(\mathbf{z}|\mathbf{x})||q(\mathbf{z}|\mathbf{x}))$。
具体来说,前向KL散度$D_{KL}(p||q)=\mathbb{E}_{\mathbf{z}\sim p(\mathbf{z})}\log \frac{p(\mathbf{z})}{q(\mathbf{z})}=\int p(\mathbf{z})\log \frac{p(\mathbf{z})}{q(\mathbf{z})}d\mathbf{z}$中,p>0的位置要求q必须同时>0(因为$\lim_{q\to 0}p\log \frac{p}{q}\to \infty$)。因此优化前向KL散度会导致q覆盖了每个p分布概率不为0的点。反过来,我们这里使用的反向KL散度$D_{KL}(q||p)=\mathbb{E}_{\mathbf{z}\sim q(\mathbf{z})}\log \frac{q(\mathbf{z})}{p(\mathbf{z})}=\int q(\mathbf{z})\log \frac{q(\mathbf{z})}{p(\mathbf{z})}d\mathbf{z}$,在p=0时保证了q必须=0。
- 前向KL散度:p>0时q>0,可能导致q平铺在p>0的区域
- 反向KL散度(使用的):p=0时q=0,可能导致q被挤压在p的一个峰上
在推导KL散度的表达式时就可以得到变分自编码器的损失函数ELBO。

(图源Lilian Weng的博客:https://lilianweng.github.io/posts/2018-08-12-vae/)
我们想同时极大化观测数据点$\mathbf{x}$的似然,以及真假编码器的分布差距,即最大化 $$\mathbb{E}_{\mathbf{z}\sim q(\mathbf{z}|\mathbf{x})}\log p(\mathbf{x}|\mathbf{z})-D_{KL}(q(\mathbf{z}|\mathbf{x})||p(\mathbf{z}))$$ 左边的是重构误差取反,右边的在先验分布为正态分布时可以显式展开。
在计算重构误差时用到了重参数技巧(reparameterization trick),即把从一个带参数的编码器采样$\mathbf{z}$,转化为从一个确定的分布(如标准正态)采样一个值,再通过将采样的值与编码器的输出(均值和方差)加减乘除得到$\mathbf{z}$。这样梯度就和采样独立开来,可以反向传播了。